There are interesting things to be learned from even the simplest queries.
For example, imagine you are asked to write a query that lists AdventureWorks product names, where the product has at least one entry in the transaction history table, but fewer than ten.
One query that meets that specification is:
SELECT
P.[Name]
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON P.ProductID = TH.ProductID
GROUP BY
P.ProductID,
P.[Name]
HAVING
COUNT_BIG(*) < 10;
The query correctly returns 23 rows. The execution plan and a sample of the data returned is shown below:
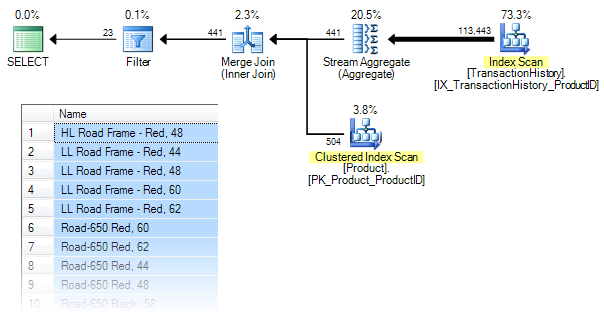
The execution plan looks a bit different from the written form of the query. The base tables are accessed in reverse order, and the aggregation is performed before the join.
The general strategy in the plan is to read all rows from the TransactionHistory table, compute the count of rows grouped by ProductID, merge join that result with the Product table on ProductID, and finally Filter to only return rows where the count is less than ten.
This ‘fully-optimized’ plan has an estimated cost of around 0.365 units.
The reason for the quote marks there is that this plan is not quite as optimal as it could be — surely it would make sense to push the Filter down past the join too?
To answer that, let’s look at some other ways to formulate this query. This being SQL, there are any number of ways to write a logically-equivalent query, so we’ll just look at a couple of interesting ones.
The first query is an attempt to reverse-engineer T-SQL from the execution plan shown previously. It joins the result of pre-aggregating the TransactionHistory table to the Product table before filtering:
SELECT
P.[Name]
FROM
(
SELECT
TH.ProductID,
cnt = COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
GROUP BY
TH.ProductID
) AS Q1
JOIN Production.Product AS P
ON P.ProductID = Q1.ProductID
WHERE
Q1.cnt < 10;
Perhaps surprisingly, we get a different execution plan:

The results are the same (23 rows) but this time the Filter is pushed below the join!
The optimizer chooses Nested Loops for the join, because the cardinality estimate for rows passing the Filter is a bit low (estimate 1 versus 23 actual). Even so, forcing a Merge Join with an OPTION (MERGE JOIN) hint still gives a plan with the Filter below the join.
In yet another variation, the < 10 predicate can be ‘manually pushed’ by specifying it in a HAVING clause in the Q1 sub-query instead of in the WHERE clause:
SELECT
P.[Name]
FROM
(
SELECT
TH.ProductID,
cnt = COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
GROUP BY
TH.ProductID
HAVING COUNT_BIG(*) < 10
) AS Q1
JOIN Production.Product AS P
ON P.ProductID = Q1.ProductID;
The reason this predicate can be pushed past the join in this query form, but not in the original formulation, is simply an optimizer limitation — it does make efforts (primarily during the simplification phase) to encourage logically-equivalent query specifications to produce the same execution plan, but the implementation is not comprehensive.
Moving on to a second example, the following query results from phrasing the requirement as:
List the products where there exists fewer than ten correlated rows in the history table”:
SELECT
P.[Name]
FROM Production.Product AS P
WHERE EXISTS
(
SELECT
*
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
HAVING
COUNT_BIG(*) < 10
);
Unfortunately, this query produces an incorrect result (86 rows):

The problem with this query is it lists products with no history rows, though the reasons behind that are interesting.
The COUNT_BIG(*) in the EXISTS clause is a scalar aggregate (meaning there is no GROUP BY clause) and scalar aggregates always produce a value, even when the input is an empty set.
In the case of the COUNT aggregate, the result of aggregating the empty set is zero (the other standard aggregates produce a NULL when presented with an empty set).
To make the point really clear, let’s look at product 709, which happens to be one for which no history rows exist:
-- Scalar aggregate
SELECT
COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = 709;
-- Vector aggregate
SELECT
COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = 709
GROUP BY
TH.ProductID;
The estimated execution plans for these two statements are almost identical:

You might expect the Stream Aggregate to have a Group By property for the second statement, but this is not the case.
The query includes ProductID = 709, so all matching rows are guaranteed to have the same value for ProductID. The optimizer recognises this, and the Group By is optimized away.
There are some minor differences between the two plans. The first qualifies for trivial plan compilation, and is subject to simple parameterization. The second plan requires cost-based optimization, and is not parameterized by SQL Server.
Still, there is nothing to indicate that one query uses a scalar aggregate and the other a vector aggregate. This is something I would like to see exposed in executions plan so I suggested it on Connect but it was closed as Won’t Fix, though they did say:
Thank you for the suggestion regarding show plan. We’ll consider it for a future release.
Anyway, running the two queries shows the difference quite clearly:

The scalar aggregate (no GROUP BY) returns a result of zero, while the vector aggregate (with a GROUP BY clause) returns nothing at all.
Returning to our EXISTS query, we could ‘fix’ it by changing the HAVING clause to reject rows where the scalar aggregate returns zero:
SELECT
P.[Name]
FROM Production.Product AS P
WHERE EXISTS
(
SELECT
*
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
HAVING
COUNT_BIG(*) BETWEEN 1 AND 9
);
The query now returns the correct 23 rows:

Unfortunately, the execution plan is less efficient now – it has an estimated cost of 0.885 compared to 0.365 for the earlier plan.
Let’s try adding a redundant GROUP BY instead of changing the HAVING clause:
SELECT
P.[Name]
FROM Production.Product AS P
WHERE EXISTS
(
SELECT
*
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
GROUP BY
TH.ProductID
HAVING
COUNT_BIG(*) < 10
);
We now get correct results (23 rows), and this is the execution plan:
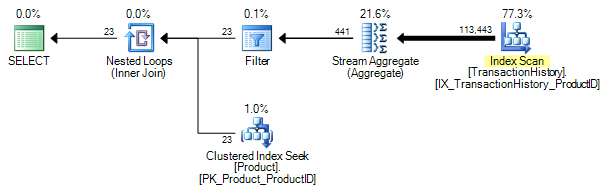
I like to compare that plan to quantum physics: if you don’t find it shocking, you haven’t understood it properly!
The addition of a redundant GROUP BY clause has resulted in the EXISTS form of the query being transformed into exactly the same optimal plan we found earlier.
What’s more (in SQL Server 2008 and later), we can replace the odd-looking redundant GROUP BY with an explicit GROUP BY on the empty set:
SELECT
P.[Name]
FROM Production.Product AS P
WHERE EXISTS
(
SELECT
*
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
GROUP BY
()
HAVING
COUNT_BIG(*) < 10
);
I offer that as an alternative because some people find it more intuitive (and it perhaps has more geek value too).
Whichever way you prefer, it’s rather satisfying to note that the result of the subquery does not exist for a particular correlated value where a vector aggregate is used.
Remember, a scalar COUNT aggregate always returns a value, even if that value is zero, so the subquery always produces a result, regardless of the ProductID being evaluated.
The following query forms also produce the optimal plan and correct results, so long as a vector aggregate is used (you can probably find more):
WHERE Clause
SELECT
P.[Name]
FROM Production.Product AS P
WHERE
(
SELECT
COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
GROUP BY
()
) < 10;
APPLY
SELECT
P.[Name]
FROM Production.Product AS P
CROSS APPLY
(
SELECT
NULL
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
GROUP BY
()
HAVING
COUNT_BIG(*) < 10
) AS CA (Dummy);
FROM Clause
SELECT
Q1.[Name]
FROM
(
SELECT
P.[Name],
cnt =
(
SELECT
COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
GROUP BY
()
)
FROM Production.Product AS P
) AS Q1
WHERE
Q1.cnt < 10;
SUM
This last example uses SUM(1) instead of COUNT and does not require a vector aggregate:
SELECT
Q.[Name]
FROM
(
SELECT
P.[Name],
cnt =
(
SELECT
SUM(1)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
)
FROM Production.Product AS P
) AS Q
WHERE
Q.cnt < 10;
The execution plan is:
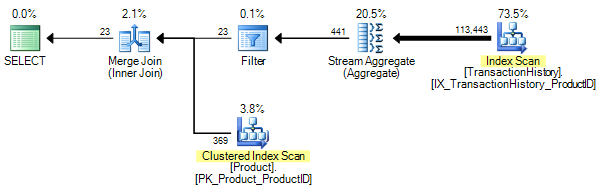
Remember the SUM of no items (the empty set) is NULL. When the cnt subquery evaluates to NULL, the predicate Q.cnt < 10 will return UNKNOWN, not TRUE. The net result is that products with no history rows will not be returned.
Final thoughts
The semantics of SQL aggregates are rather odd in places. It definitely pays to get to know the rules, and to be careful to check whether your queries are using scalar or vector aggregates.
As we have seen, query plans do not show in which ‘mode’ an aggregate is running. Getting it wrong can cause poor performance, wrong results, or both.
© Paul White
email: SQLkiwi@gmail.com
twitter: @SQL_Kiwi
No comments:
Post a Comment
All comments are reviewed before publication.