Can DELETE operations cause pages to split?
Yes. It sounds counter-intuitive on the face of it. Deleting rows frees up space on a page, and page splitting occurs when a page needs additional space. Nevertheless, there are circumstances when deleting rows causes them to expand before they can be deleted.
The mechanism at work here is row versioning (extract from the documentation quoted below):
Space used in data rows
Each database row may use up to 14 bytes at the end of the row for row versioning information. The row versioning information contains the transaction sequence number of the transaction that committed the version and the pointer to the versioned row. These 14 bytes are added the first time the row is modified, or when a new row is inserted, under any of these conditions:
READ_COMMITTED_SNAPSHOTorALLOW_SNAPSHOT_ISOLATIONoptions are ON.- The table has a trigger.
- Multiple Active Results Sets (MARS) is being used.
- Online index build operations are currently running on the table.
Isolation Levels
The relationship between row-versioning isolation levels (the first bullet point) and page splits is reasonably clear. Any data that existed before either of the isolation levels was enabled will need to have the 14 bytes added by future data modifications, perhaps causing pages to split.
In this scenario, tables will likely contain a mix of records to start with, but over time (particularly as index maintenance is performed) the database will end up with row versions on most records, reducing the chances of a page split for that particular reason.
There is nevertheless a window of opportunity where adding the 14 bytes to an existing record could cause a page split. No doubt there’s a recommendation out there somewhere to rebuild all tables and indexes when enabling or disabling a row-versioning isolation level on a database. This is not all that interesting though, so let’s look at the second bullet point instead:
Triggers
The documentation says that versioning information is added if the table has a trigger. What it doesn’t say is:
-
The extra bytes for row versioning can be added even where both
READ_COMMITTED_SNAPSHOTandSNAPSHOTisolation are setOFF. -
This only applies to
AFTERtriggers, notINSTEAD OFtriggers -
The
AFTERtrigger also needs to be enabled to generate row versions, the mere existence of a trigger is not enough. -
There is a very important exception to all the above…
SQL Server can still avoid adding the row-versioning information even where an enabled AFTER TRIGGER exists.
The remainder of this post assumes that both row-versioning isolation levels are OFF.
Avoiding Row Versioning with Triggers
To explore this behaviour in a bit of detail, we’ll need a test rig:
USE tempdb;
GO
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
DROP TABLE dbo.Test;
GO
-- Test table
CREATE TABLE dbo.Test
(
ID integer IDENTITY PRIMARY KEY,
Column01 nvarchar(20) NULL,
Column02 nvarchar(4000) NULL,
);
GO
-- Add some rows
INSERT dbo.Test WITH (TABLOCKX)
(Column01)
SELECT TOP (100000)
CONVERT(nvarchar(20), N'X')
FROM sys.columns AS C1
CROSS JOIN sys.columns AS C2
CROSS JOIN sys.columns AS C3
OPTION (MAXDOP 1);
GO
-- A trigger that does nothing
CREATE TRIGGER trg
ON dbo.Test
AFTER DELETE
AS RETURN;
GO
-- Write any dirty pages to disk
CHECKPOINT;
GO
-- Physical storage before any changes
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.max_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
NULL,
NULL,
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0;
GO
-- Buffer pool pages before any changes
SELECT
DOBD.[file_id],
DOBD.page_id,
DOBD.page_type,
DOBD.row_count,
DOBD.free_space_in_bytes,
DOBD.is_modified
FROM sys.partitions AS P
JOIN sys.allocation_units AS AU
ON AU.container_id = P.hobt_id
JOIN sys.dm_os_buffer_descriptors AS DOBD
ON DOBD.allocation_unit_id = AU.allocation_unit_id
WHERE
P.[object_id] = OBJECT_ID(N'dbo.Test', N'U')
ORDER BY
DOBD.page_id;
GO
SET STATISTICS IO ON;
-- Delete 1 in 10 rows
DELETE dbo.Test
WHERE ID % 10 = 0;
SET STATISTICS IO OFF;
GO
SELECT
[Page Splits] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL,NULL) AS FD
WHERE
FD.[Transaction Name] = N'SplitPage';
GO
-- Ensure ghosted records are processed so
-- we see accurate per-page row counts
DBCC FORCEGHOSTCLEANUP;
GO
-- Physical storage after the delete operation
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.max_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
NULL,
NULL,
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0;
GO
-- Buffer pool pages after the delete operation
SELECT
DOBD.[file_id],
DOBD.page_id,
DOBD.page_type,
DOBD.row_count,
DOBD.free_space_in_bytes,
DOBD.is_modified
FROM sys.partitions AS P
JOIN sys.allocation_units AS AU
ON AU.container_id = P.hobt_id
JOIN sys.dm_os_buffer_descriptors AS DOBD
ON DOBD.allocation_unit_id = AU.allocation_unit_id
WHERE
P.[object_id] = OBJECT_ID(N'dbo.Test', N'U')
ORDER BY
DOBD.page_id;
GO
--DBCC TRACEON (3604);
--DBCC PAGE (tempdb, 1, 4720, 3);
The script performs the following actions:
- Creates a clustered table with an
IDand two data columns - Adds 100,000 rows each with a single ‘X’ character in the first column, and
NULLin the second - Creates an
AFTER DELETEtrigger that does nothing at all except exist and be enabled - Displays physical storage and buffer pool information using DMVs
- Deletes every tenth row in the table
- Shows the number of leaf-level page splits that occurred
- Displays the physical storage and buffer pool information again
Test One – Clustered Table
Typical output:
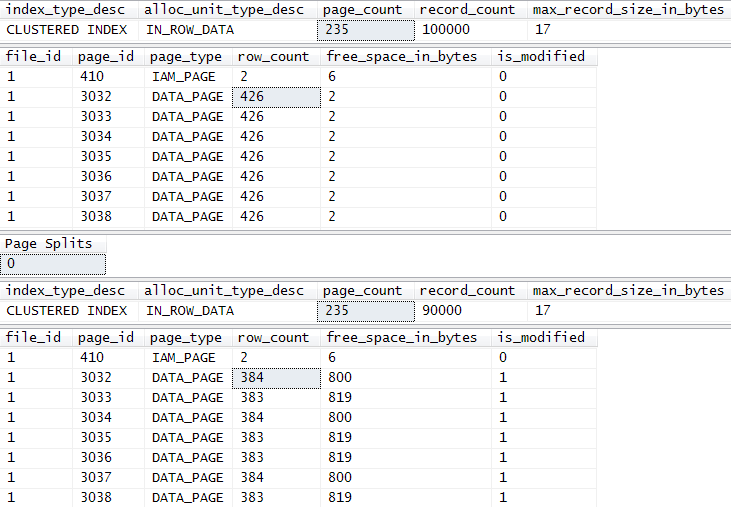
There are 235 data pages with a maximum physical record size of 17 bytes before and after the delete. Before the delete, each data page contains 426 rows with 2 bytes of free space.
After the DELETE:
- A total of 10,000 records have been deleted
- The data page count remains at 235
- The maximum record size is still 17 bytes
- Each data page has lost 42 or 43 rows
- The free space on each page has risen to 800 or 819 bytes
- All data pages are marked as being modified in memory
- A total of 237 logical reads are reported
No surprises there.
Test Two – Clustered Table
Now, run the script again with the only change being that Column01 is defined as nvarchar(22) instead of nvarchar(20).
The ‘before’ picture is the same as before, but the situation after the DELETE is very different:

There have been 234 page splits, increasing the data page count from 235 pages to 469 pages, and halving the number of rows on each data page.
The number of reads reported has also blown out from 237 previously to 2342 logical reads in this run (a factor of ten worse).
Explanation
The cause of the page splitting is that the deleted records must be versioned.
SQL Server 2005 and later uses the version store to build the inserted and deleted pseudo-tables used by AFTER triggers. Where the data has no pre-existing versioning data, adding the 14 bytes will result in a clustered index page split if the page contains insufficient free space to accommodate this expansion.
Temporarily turning off ghost record cleanup using global trace flag 661 and examining an affected data page using DBCC PAGE shows the following (remember to turn the trace flag off afterward if you try this):

Slots 8 and 10 on this page hold records that were unaffected by the DELETE; the physical row length is 17 bytes as displayed previously. The record that was in slot 9 has been deleted. It is a ghost record with versioning information added. The record size is 17 + 14 = 31 bytes, and this expansion with only 2 bytes of free space on the page caused it to split.
This explains why the nvarchar(22) DELETE test caused page splitting, but why didn’t the original nvarchar(20) script behave the same?
There is a performance optimization that can avoid adding row versioning information, but only if the table cannot generate ROW_OVERFLOW or LOB allocation units.
This means that the definition of the table must not allow for LOBs or for the possibility of variable length columns moving off row. The actual size of the data stored is immaterial — it is the potential size that matters.
In our test, the nvarchar(22) column definition caused the maximum possible INROW size to just exceed the 8060 byte limit. (The exact INROW limit also depends on the table definition; marking one of the data columns SPARSE would reduce the limit).
Heaps of Forwarded Ghosts
Page splitting only occurs in index structures, are heap-structured tables affected by this issue too?
It is true that heap pages do not split, but when a heap row needs to expand, the engine will move the row to another page if insufficient free space exists on the current page. When the storage engine does this, it leaves a forward pointer behind to avoid updating all nonclustered indexes to reflect the new physical row locator.
For a heap table with an active AFTER trigger, and a LOB column (or the possibility of row-overflow) the row has to be versioned and ghosted.
If the page contains insufficient free space to accommodate the versioning, the row moves to another page leaving a forwarding stub behind. This results in a forwarded ghost record.
Ghost clean-up will normally remove this record pretty quickly, so we will need to disable that process temporarily. The following script creates the special circumstances necessary to produce a forwarded ghost record this way (note this script is for test systems only and should not be run in tempdb):
USE Sandpit;
GO
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END
GO
-- Heap test
CREATE TABLE dbo.Test
(
ID integer IDENTITY PRIMARY KEY NONCLUSTERED,
Column01 nvarchar(22) NULL,
Column02 nvarchar(4000) NULL
);
GO
-- Add some all-NULL rows
INSERT dbo.Test WITH (TABLOCKX)
(Column01)
SELECT TOP (100000)
NULL
FROM sys.columns AS C1
CROSS JOIN sys.columns AS C2
CROSS JOIN sys.columns AS C3
OPTION (MAXDOP 1);
GO
-- Ensure rows are tightly packed
ALTER TABLE dbo.Test
REBUILD
WITH (MAXDOP = 1);
GO
-- A trigger that does nothing
CREATE TRIGGER trg
ON dbo.Test
AFTER DELETE
AS RETURN;
GO
-- Write any dirty pages to disk
CHECKPOINT;
GO
-- Physical storage before any changes
SELECT
DDIPS.index_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.max_record_size_in_bytes,
DDIPS.ghost_record_count,
DDIPS.forwarded_record_count
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
NULL,
NULL,
'DETAILED'
) AS DDIPS
WHERE
DDIPS.alloc_unit_type_desc = N'IN_ROW_DATA'
AND DDIPS.index_level = 0;
GO
-- Buffer pool pages before any changes
SELECT
DOBD.[file_id],
DOBD.page_id,
DOBD.page_type,
DOBD.row_count,
DOBD.free_space_in_bytes,
DOBD.is_modified
FROM sys.partitions AS P
JOIN sys.allocation_units AS AU
ON AU.container_id = P.hobt_id
JOIN sys.dm_os_buffer_descriptors AS DOBD
ON DOBD.allocation_unit_id = AU.allocation_unit_id
WHERE
P.[object_id] = OBJECT_ID(N'dbo.Test', N'U')
AND DOBD.page_type = N'DATA_PAGE'
ORDER BY
DOBD.page_id;
GO
-- Disable ghost clean-up
DBCC TRACEON (661, -1);
GO
SET STATISTICS IO ON;
-- Delete three records on the same page
DELETE dbo.Test
WHERE ID BETWEEN 1 AND 3;
SET STATISTICS IO OFF;
GO
-- Physical storage after the delete operation
SELECT
DDIPS.index_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.max_record_size_in_bytes,
DDIPS.ghost_record_count,
DDIPS.forwarded_record_count
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
NULL,
NULL,
'DETAILED'
) AS DDIPS
WHERE
DDIPS.alloc_unit_type_desc = N'IN_ROW_DATA'
AND DDIPS.index_level = 0;
GO
-- Buffer pool pages after the delete operation
SELECT
DOBD.[file_id],
DOBD.page_id,
DOBD.page_type,
DOBD.row_count,
DOBD.free_space_in_bytes,
DOBD.is_modified
FROM sys.partitions AS P
JOIN sys.allocation_units AS AU
ON AU.container_id = P.hobt_id
JOIN sys.dm_os_buffer_descriptors AS DOBD
ON DOBD.allocation_unit_id = AU.allocation_unit_id
WHERE
P.[object_id] = OBJECT_ID(N'dbo.Test', N'U')
AND DOBD.page_type = N'DATA_PAGE'
ORDER BY
DOBD.page_id;
GO
-- View the appropriate page
--DBCC TRACEON (3604);
--DBCC PAGE (0, 1, 339408, 3);
GO
-- Enable ghost clean-up
DBCC TRACEOFF (661, -1);
The page we are looking for will be one of the two marked as modified in the buffer pool. Example output, showing page 453648 receiving a versioned forwarded ghost record:

Partial DBCC PAGE output for the highlighted page:

And from a different test run on SQL Server 2017:
Slot 480 Offset 0x1519 Length 32
Record Type = FORWARDED_RECORD Record Attributes = VARIABLE_COLUMNS VERSIONING_INFO FORWARDED_GHOST
Record Size = 32
Memory Dump @0x0000004782BFB519
0000000000000000: 62010400 01001280 000498a1 00000100 02000801 b..........¡........
0000000000000014: 00000100 020016c4 55000000 .......ÄU...
Version Information =
Transaction Timestamp: 5620758
Version Pointer: (file 1 page 264 currentSlotId 2)
Forwarded from = file 1 page 41368 slot 2
Summary
If you ever wonder why your deletes are so slow, it is worth checking to see if you are suffering from page splitting due to an enabled trigger and a table definition that allows for LOB allocations or ROW_OVERFLOW.
Any table with a LOB column (including the max data types) qualifies, as does one with even a surprisingly small number of variable-length columns, as shown in the examples in this post.
This is a great reason to avoid using max or old-style LOB data types unnecessarily, and to be careful about the maximum length of ‘normal’ variable-length data types too.
Remember, it is the potential maximum row size that is important, not the actual row size.
On a related note, do you remember that deletes on a heap can only deallocate empty pages if a table lock is acquired? A table definition that allows for LOB or ROW_OVERFLOW prevents that optimization too.
If your heaps are growing despite DELETE WITH (TABLOCKX), check the maximum possible row length! You could also convert them to clustered tables as well, of course, but that’s a quite different debate.
I would like to acknowledge and thank SQL Server MVP Dmitri V. Korotkevitch who first brought the basic issue to my attention with UPDATE queries. I would encourage you to also read his blog entry showing how this behaviour also affects UPDATE queries, resulting in slow performance and excessive fragmentation.
© Paul White
email: SQLkiwi@gmail.com
twitter: @SQL_Kiwi

No comments:
Post a Comment
All comments are reviewed before publication.