Estimated row counts on Key or RID Lookups where a filtering predicate is applied can be wrong in SSMS execution plans.
This error does not affect the optimizer’s ultimate plan selection, but it does look odd.
There are other cases where estimated row counts are inconsistent (for defensible reasons) but the behaviour shown in this post in certainly a bug.
SQL Server 2005
The following AdventureWorks sample query displays TransactionHistory table information for ProductID #1 and the last three months of 2003.
- Note
- If you are using a more recent version of AdventureWorks, you will need to change the year from 2003 (to 2007 or 2013, depending).
SELECT
TH.ProductID,
TH.TransactionID,
TH.TransactionDate
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = 1
AND TH.TransactionDate BETWEEN '20030901' AND '20031231';
(On SQL Server 2014 or later, you also need to use the original cardinality estimation model if you want to see the same estimates. The problem still exists with the latest CE, but the numbers will be slightly different from those shown).
The execution plan is:
The execution flow is pretty straightforward:
- The plan seeks a nonclustered index on the
ProductIDcolumn to find rows whereProductID = 1. This non-clustered index is keyed onProductIDalone, but the index also includes theTransactionIDclustering key (to point to the parent row in the base table). - The index does not cover the query (the
TransactionDatecolumn is not present in the index) so a Key Lookup is required for theTransactionDatecolumn. - The Nested Loops Join drives a look up process such that each row from the Index Seek on
ProductID = 1results in a lookup in the clustered index to find theTransactionDatevalue for that row. - A final Filter operator passes only rows that meet the date range condition.
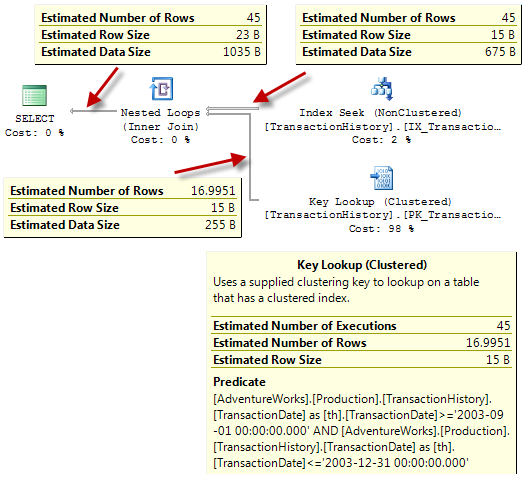
The next diagram shows the same plan with cardinality estimates and extra details for the Key Lookup:

The cardinality estimate at the Index Seek is exactly correct.
The table is not very large, there are up-to-date statistics associated with the index, so this is as expected. If you run a query to find all rows in the TransactionHistory table for ProductID #1, 45 rows will indeed be returned.
The estimate for the Key Lookup is exactly correct.
Each Lookup into the Clustered Index to find the TransactionDate is guaranteed to return exactly one row (each nonclustered index entry is associated with exactly one base table row). The Key Lookup is expected to be executed 45 times (shown circled).
The estimate for the Inner Join is exactly correct
45 rows from the seek joining to one row each time from the Lookup, gives a total of 45 rows.
The Filter estimate is also good:
SQL Server estimates that of the 45 rows entering the filter, 16.9951 rows will match the specified range of transaction dates. In reality, only 11 rows are produced by this query, but that small difference in estimates is quite normal and certainly nothing to worry about here. Keep that estimate of 16.9951 rows in mind.
SQL Server 2008 - 2019
The same query executed against an identical copy of AdventureWorks on SQL Server 2008 or later (tested up to SQL Server 2019 CTP 2.0) produces a quite different execution plan:
Instead of an explicit Filter to find rows with the requested date range, the optimizer has pushed the date predicate down to the Key Lookup (which now has a residual predicate on TransactionDate). This is a good optimization in general terms. It makes sense to filter rows as early as possible.
Unfortunately, it has made a bit of a mess of the cardinality estimates in the process.
The post-Filter estimate of 16.9951 rows seen in the 2005 plan has been moved to the Key Lookup.
Instead of estimating one row per Lookup, the plan now suggests that 16.9951 rows will be produced by each clustered index lookup — clearly not right!
To my way of thinking, the execution plan cardinality estimates should look something like this:

As shown, I personally prefer to see the inner side of a Nested Loops Join estimate the number of rows per execution, but I understand I may be in a minority on this point.
If the estimate were aggregated over the expected number of executions, the inner-side estimate would be also be 16.9951 (45 executions * 0.37767 per execution).
Cause
The query tree produced by the 2008+ optimizer looks much the same as the 2005 version — the explicit Filter is still present.
However, a post-optimization rewrite occurs in the ‘copy out’ phase that moves the Filter into the Key Lookup, resulting in a residual predicate on that operator. This rewrite applies to regular scans and seeks too (so all residual predicates on scans and seeks are a result of this late rewrite).
I would like to thank Dima Piliugin (twitter | blog) for introducing me to undocumented trace flag 9130, which disables the rewrite from Filter + (Scan or Seek) to (Scan or Seek) + Residual Predicate.
Enabling this trace flag retains the Filter in the final execution plan, resulting in a SQL Server 2008+ plan that mirrors the 2005 version, with correct estimates.
The bug is that this rewrite that does not correctly update cardinality estimates when the Filter is pushed down to a Lookup.
I should stress that the rewrite occurs after all cost-based decisions have been made, so the incorrect estimate just looks odd and makes plan analysis harder than it ought to be.
Cardinality estimates with regular scans and seeks appear to work correctly, as far as I can tell. The bug applies to both RID lookups and Key Lookups where a residual predicate is applied.
Workarounds
Using the trace flag is not a workaround because (a) it is undocumented and unsupported; and (b) it results in a less efficient plan where rows are filtered much later than is optimal.
One genuine workaround is to provide a covering nonclustered index (because avoiding the Lookup avoids the problem):
CREATE INDEX nc1
ON Production.TransactionHistory (ProductID)
INCLUDE (TransactionDate);
With the TransactionDate filter applied as a residual predicate in the same operator as the seek, the final estimate is as expected:

We could also force the use of the ultimate covering index (the clustered one) with a suitable table index hint:
SELECT
TH.ProductID,
TH.TransactionID,
TH.TransactionDate
FROM Production.TransactionHistory AS TH
WITH (INDEX(1)) -- new!
WHERE
TH.ProductID = 1
AND TH.TransactionDate BETWEEN '20030901' AND '20031231';
(again you may need to modify the year part of those dates depending on the AdventureWorks version you are using.)

The estimate is now correct at 16.9951.
Fixed SQL Sentry Plan Explorer from build 7.2.42.0
After this post was published on October 15 2012, I was contacted by the SQL Sentry people to see if a good workaround could be incorporated in their free Plan Explorer product.
I was happy to provide some testing and general feedback during a process that ultimately resulted in a new build being released on 31 October 2012. If only SSMS limitations could be addressed so quickly! Once you upgrade to the new version, the plan displayed for our test query is:

This is exactly the representation we would expect if the SQL Server bug did not exist (note that Plan Explorer aggregates estimated inner-side executions for you, and rounds to integer).
Thanks and well done to the SQL Sentry team, especially Brooke Philpott (@MacroMullet).
Summary
Providing a covering nonclustered index to avoid Lookups for all possible queries is not always practical. Scanning the clustered index will rarely be the optimal choice either. Nevertheless, these are the best workarounds we have today in SSMS.
Watch out for poor cardinality estimates when a residual predicate is applied as part of a Lookup.
This particular cardinality estimation issue does not affect the final plan choice (the internal estimates are correct) but it does look odd and will confuse people when analysing query plans in SSMS.
If you think this situation should be improved, please vote for this Azure Feedback bug Cardinality Estimation Error With Pushed Predicate on a Lookup.
The original Connect item was closed as Won’t Fix with this message:
Thank you for submitting this feedback. After carefully evaluating all of the bugs in our pipeline, we are closing bugs that we will not fix in the current or future versions of SQL Server. This is because the fix is risky to implement.
…but that doesn’t mean the Azure Feedback item won’t be revisited if it gets enough votes, though it is currently marked Unplanned.
Update August 2020
There is a fix for this planned for the release after SQL Server 2019 (compatibility level 160). A quote from Joe Sack at Microsoft:
this is a planned fix for vNext and for Azure SQL Database under the new database compatibility level once in preview.
© Paul White
email: SQLkiwi@gmail.com
twitter: @SQL_Kiwi
No comments:
Post a Comment
All comments are reviewed before publication.