This post is in two parts. The first part looks at the Switch execution plan operator. The second part is about an invisible plan operator and cardinality estimates on filtered indexes.
Part 1: My Switch Is Bored
This is the rare Switch execution plan operator:

The documentation says:
Switch is a special type of concatenation iterator that has n inputs.
An expression is associated with each Switch operator. Depending on the return value of the expression (between 0 and n-1), Switch copies the appropriate input stream to the output stream.
One use of Switch is to implement query plans involving fast forward cursors with certain operators such as the TOP operator.
Switch is both a logical and physical operator.
Based on that description, I tried to produce an execution plan containing a Switch operator using a Fast Forward Cursor and TOP operator, but had no luck.
One way to produce a Switch requires a local partitioned view:
CREATE TABLE dbo.T1
(
c1 integer NOT NULL
CHECK (c1 BETWEEN 00 AND 24)
);
CREATE TABLE dbo.T2
(
c1 integer NOT NULL
CHECK (c1 BETWEEN 25 AND 49)
);
CREATE TABLE dbo.T3
(
c1 integer NOT NULL
CHECK (c1 BETWEEN 50 AND 74)
);
CREATE TABLE dbo.T4
(
c1 integer NOT NULL
CHECK (c1 BETWEEN 75 AND 99)
);
GO
CREATE VIEW dbo.V1
WITH SCHEMABINDING
AS
SELECT c1
FROM dbo.T1
UNION ALL
SELECT c1
FROM dbo.T2
UNION ALL
SELECT c1
FROM dbo.T3
UNION ALL
SELECT c1
FROM dbo.T4;
The partitioned view also needs to be updatable. We need to add some primary keys to meet that requirement:
ALTER TABLE dbo.T1
ADD CONSTRAINT PK_T1
PRIMARY KEY (c1);
ALTER TABLE dbo.T2
ADD CONSTRAINT PK_T2
PRIMARY KEY (c1);
ALTER TABLE dbo.T3
ADD CONSTRAINT PK_T3
PRIMARY KEY (c1);
ALTER TABLE dbo.T4
ADD CONSTRAINT PK_T4
PRIMARY KEY (c1);
We also need an INSERT statement that targets the view. To see a Switch operator, we need to perform a single-row insert (multi-row inserts use a different plan shape):
INSERT dbo.V1
(c1)
VALUES
(1);
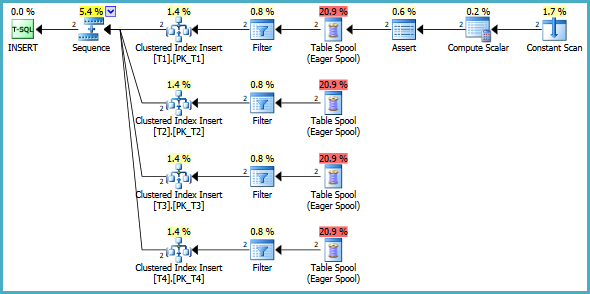
The execution plan is:

The logic is as follows:
- The Constant Scan manufactures a single row with no columns.
- The Compute Scalar calculates which partition of the view the new value should go in.
- The Assert checks that the computed partition number is not null (if it is, an error is returned).
- The Nested Loops Join executes exactly once, with the partition number as an outer reference (correlated parameter).
- The Switch operator checks the value of the parameter and executes the corresponding input only.
- If the partition number is 0, the uppermost Clustered Index Insert is executed, adding a row to table
T1. - If the partition number is 1, the next lower Clustered Index Insert is executed, adding a row to table
T2 - …and so on.
- If the partition number is 0, the uppermost Clustered Index Insert is executed, adding a row to table
In case you were wondering, here is a query and associated execution plan for a multi-row insert to the partitioned view:
INSERT dbo.V1
(c1)
VALUES
(1),
(2);
My guess is that many of the old strategies that used a Switch operator have been replaced over time, using things like a regular Concatenation Union All combined with Start-Up Filters on the inputs.
Other new (relative to the Switch operator) features like table partitioning have specific execution plan support that doesn’t need the Switch operator either.
Please let me know if you encounter an execution plan using the Switch operator — it must be very bored if a single-row insert to a partitioned view is the only modern usage!
Please let me know about any Switch plans you come across on a modern instance of SQL Server.
Part 2: Invisible Plan Operators
The second part of this post uses an example based on an execution plan question submitted to me by Dave Ballantyne.
The problem
The issue revolves around a query on a calendar table. The script below creates a simplified version and adds 100 years of per-day information to it:
USE tempdb;
GO
CREATE TABLE dbo.Calendar
(
dt date NOT NULL,
isWeekday bit NOT NULL,
theYear smallint NOT NULL,
CONSTRAINT PK__dbo_Calendar_dt
PRIMARY KEY CLUSTERED (dt)
);
GO
-- Monday is the first day of the week for me
SET DATEFIRST 1;
-- Add 100 years of data
INSERT dbo.Calendar
WITH (TABLOCKX)
(
dt,
isWeekday,
theYear
)
SELECT
CA.dt,
isWeekday =
CASE
WHEN DATEPART(WEEKDAY, CA.dt) IN (6, 7)
THEN 0
ELSE 1
END,
theYear = YEAR(CA.dt)
FROM Sandpit.dbo.Numbers AS N
CROSS APPLY
(
VALUES
(
DATEADD
(
DAY,
N.n - 1,
CONVERT(date, '01 Jan 2000', 113)
)
)
) AS CA (dt)
WHERE
N.n BETWEEN 1 AND 36525;
The following query counts the number of weekend days in 2013:
SELECT
[Days] = COUNT_BIG(*)
FROM dbo.Calendar AS C
WHERE
C.theYear = 2013
AND C.isWeekday = 0;
It returns the correct result (104) using the following execution plan:
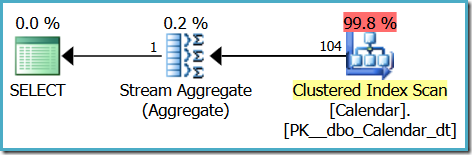
The query optimizer has managed to estimate the number of rows returned from the table exactly, based purely on the default statistics created separately on the two columns referenced in the query’s WHERE clause. (Well, almost exactly, the unrounded estimate is 104.289 rows.)
- Note
- The above is true for the original cardinality estimation model. The estimate using the model introduced in SQL Server 2014 is less accurate (195.103 rows). The key points in the discussion that follows are independent of the CE model, but if you want to see the same estimates as shown above, use trace flag 9481 or the query hint
USE HINT ('FORCE_LEGACY_CARDINALITY_ESTIMATION').
Invisible filter
There is already an invisible operator in this query plan — a Filter operator used to apply the WHERE clause predicates. We can reveal it by re-running the query with the enormously useful (but undocumented) trace flag 9130 enabled:

Now we can see the full picture: The whole table is scanned, returning all 36,525 rows, before the Filter narrows that down to just the 104 we want. Without trace flag 9130, the Filter is pushed down into the Clustered Index Scan as a residual predicate. The estimate for the Filter is still very good:

Adding a filtered index
Looking to improve the performance of this query, Dave added the following filtered index to the Calendar table:
CREATE NONCLUSTERED INDEX
Weekends
ON dbo.Calendar
(theYear)
WHERE
isWeekday = 0;
The original query now produces a more efficient plan:
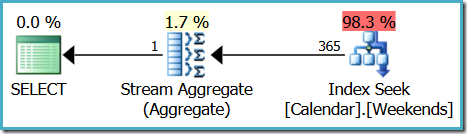
Unfortunately, the estimated number of rows produced by the seek is now wrong (365 instead of 104):

What’s going on? The estimate was much better before we added the filtered index.
Explanation
Using trace flags 3604, 8606, and 8612, we can see that the cardinality estimates were exactly right initially:
*** Join-collapsed Tree: ***
LogOp_GbAgg OUT(COL: Expr1001 ,) [ Card=1 ]
LogOp_Select [ Card=104 ]
LogOp_Get TBL: dbo.Calendar [ Card=36525 ]
ScaOp_Logical x_lopAnd
ScaOp_Comp x_cmpEq
ScaOp_Identifier QCOL: [C].theYear
ScaOp_Const Value=2013
ScaOp_Comp x_cmpEq
ScaOp_Identifier QCOL: [C].isWeekday
ScaOp_Const Value=0
AncOp_PrjList
AncOp_PrjEl COL: Expr1001
ScaOp_AggFunc stopCountBig Transformed
ScaOp_Const Value=0
The highlighted information shows the initial cardinality estimates for the base table (36,525 rows), the result of applying the two relational selections (filters) in our WHERE clause (104 rows), and after performing the COUNT_BIG(*) group by aggregate (1 row). All of these are correct, but that was before cost-based optimization got involved.
Cost-based optimization
When cost-based optimization starts up, the logical tree above is copied into a structure (the ‘memo’) that has one group per logical operation.
The logical read of the base table (LogOp_Get) ends up in group 7; the two predicates (LogOp_Select) end up in group 8 (with the details of the selections in subgroups 0-6). These two groups still have the correct cardinalities as trace flag 8608 output (initial memo contents) shows:
Group 8: Card=104 0 LogOp_Select 7 6 Group 7: Card=36525 0 LogOp_Get
During cost-based optimization, a rule called SelToIdxStrategy runs on group 8. Its job is to match logical selections to indexable expressions. It successfully matches the selections (theYear = 2013and is Weekday = 0) to the filtered index, and writes a new alternative into the memo structure.
The new alternative is entered into group 8 as option 1 (option 0 was the original LogOp_Select):
Apply Rule SelToIdxStrategy - Sel Table -> Index expression
Args: Grp 8 0 LogOp_Select 7 6
Rule Result: group=8 1 <SelToIdxStrategy>PhyOp_NOP 22
Subst:
PhyOp_NOP
LogOp_SelectIdx(1) [ Card=365 ]
LogOp_GetIdx TBL: dbo.Calendar [ Card=10436 ]
ScaOp_Comp x_cmpEq
ScaOp_Identifier QCOL: [C].theYear
ScaOp_Const Value=2013
PhyOp_NOP (no operation) replaces the predicate isWeekday = 0 because that is covered by the filtered index .
Below that, the LogOp_GetIdx (unrestricted read of an index) goes into group 21, and the LogOp_SelectIdx (selection on an index) is placed in group 22, operating on the result of group 21. The definition of the comparison the Year = 2013 (ScaOp_Comp downwards) was already present in the memo starting at group 2, so no new memo group is created for that.
New Cardinality Estimates
The new memo groups require two new cardinality estimates to be derived. First, LogOp_Idx gets a predicted cardinality of 10,436. This number comes from the filtered index statistics:
DBCC SHOW_STATISTICS (Calendar, Weekends)
WITH STAT_HEADER;
| Name | Updated | Rows | Rows Sampled | Steps |
|---|---|---|---|---|
| Weekends | Jun 11 2013 4:36PM | 10436 | 10436 | 51 |
The second new cardinality derivation is for LogOp_SelectIdx applying the predicate (theYear = 2013). To get a number for this, the cardinality estimator uses statistics for the column theYear, producing an estimate of 365 rows (since there are 365 days in 2013):
DBCC SHOW_STATISTICS (Calendar, theYear)
WITH HISTOGRAM;
| RANGE_HI_KEY | RANGE_ROWS | EQ_ROWS |
|---|---|---|
| 2013 | 0 | 365 |
This is where the mistake happens. Cardinality estimation should have used the filtered index statistics here, to get an estimate of 104 rows:
DBCC SHOW_STATISTICS (Calendar, Weekends)
WITH HISTOGRAM;
| RANGE_HI_KEY | RANGE_ROWS | EQ_ROWS |
|---|---|---|
| 2012 | 105 | 105 |
| 2014 | 104 | 104 |
Unfortunately, the logic has lost sight of the link between the read of the filtered index (LogOp_GetIdx) in group 22, and the selection on that index (LogOp_SelectIdx) that it is deriving a cardinality estimate for, in group 21.
The correct cardinality estimate (104 rows) is still present in the memo, attached to group 8, but that group now has a PhyOp_NOP implementation.
Skipping over the rest of cost-based optimization, we can see the optimizer’s final output using trace flag 8607:
*** Output Tree: ***
PhyOp_StreamGbAgg( ) [ Card=1 ]
PhyOp_NOP [ Card=104 ]
PhyOp_Range TBL: dbo.Calendar [ Card=365 ]
ScaOp_Comp x_cmpEq
ScaOp_Identifier QCOL: [C].theYear
ScaOp_Const Value=2013
AncOp_PrjList
AncOp_PrjEl COL: Expr1001
ScaOp_AggFunc stopCountBig Transformed
ScaOp_Const Value=0
This output shows the (incorrect, but understandable) 365 row estimate for the index range operation, and the correct 104 estimate still attached to PhyOp_NOP.
This tree still has to go through a few post-optimizer rewrites and ‘copy out’ from the memo structure into a form suitable for the execution engine. One step in this process removes PhyOp_NOP, discarding its 104-row cardinality estimate as it does so.
To finish this section on a more positive note, consider what happens if we add an OVER clause to the query aggregate. This isn’t intended to be a ‘fix’ of any sort, I just want to show you that the 104 estimate can survive and be used if later cardinality estimation needs it:
SELECT
[Days] = COUNT_BIG(*) OVER ()
FROM dbo.Calendar AS C
WHERE
C.theYear = 2013
AND C.isWeekday = 0;
The estimated execution plan is:

Note the 365 estimate at the Index Seek, but the 104 lives again at the Segment! We can imagine the lost predicate isWeekday = 0 as sitting between the seek and the segment in an invisible Filter operator that drops the estimate from 365 to 104.
Even though the NOP group is removed after optimization (so we don’t see it in the execution plan) bear in mind that all cost-based choices were made with the 104-row memo group present, so although things look a bit odd, it shouldn’t affect the optimizer’s plan selection.
I should also mention that we can work around the estimation issue by including the index’s filtering columns in the index key:
CREATE NONCLUSTERED INDEX
Weekends
ON dbo.Calendar
(
theYear,
isWeekday
)
WHERE
isWeekday = 0
WITH
(
DROP_EXISTING = ON
);
There are some downsides to doing this, including that changes to the isWeekday column may now require Halloween Protection, but that is unlikely to be a problem for a static calendar table!
With the updated index in place, the original query produces an execution plan with the correct cardinality estimation showing at the Index Seek:

© Paul White
email: SQLkiwi@gmail.com
twitter: @SQL_Kiwi
No comments:
Post a Comment
All comments are reviewed before publication.