SQL Server row-mode sorts generally use a custom implementation of the well-known merge sort algorithm to order data.
As a comparison-based algorithm, this performs a large number of value comparisons during sorting—usually many more than the number of items to sort.
Although each comparison is typically not expensive, even moderately sized sorting can involve a very large number of comparisons.
SQL Server can be called upon to sort a variety of data types. To facilitate this, the sorting code normally calls out to a specific comparator to determine how two compared values should sort: lower, higher, or equal.
Although calling comparator code has low overhead, performing enough of them can cause noticeable performance differences.
To address this, SQL Server has always (since at least version 7) supported a fast key optimization for simple data types. This optimization performs the comparison using highly optimized inline code rather than calling out to a separate routine.
The supported data types are:
- tinyint, smallint, integer
- money, smallmoney
- datetime, smalldatetime
- float (NOT NULL only)
All listed types can use the fast key optimization when NULL or NOT NULL except float, which can be optimized only when NOT NULL.
No other data types can use fast key optimization, notably not bigint, decimal, or any of the string types.
To benefit from the fast key optimization, at least the first item in the sort ordering should be one of the supported types.
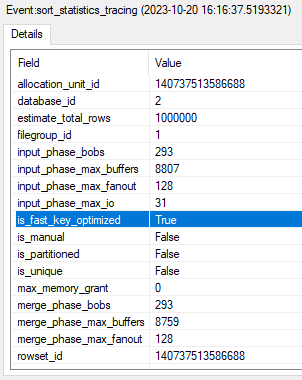
You can tell if the fast key optimization has been used by monitoring the extended event sort_statistics_tracing and the is_fast_key_optimized field. This will be true when the fast key optimization is used.
Demo
Create a table with a million random integers:
CREATE TABLE dbo.Sort
(
c1 integer NOT NULL
);
GO
INSERT dbo.Sort
WITH (TABLOCKX)
(c1)
SELECT
CONVERT(integer, CRYPT_GEN_RANDOM(4))
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
WHERE
SV1.[type] = N'P'
AND SV2.[type] = N'P'
AND SV1.number BETWEEN 1 AND 1000
AND SV2.number BETWEEN 1 AND 1000
OPTION (MAXDOP 1);
Sort with fast key optimization enabled:
SELECT
S.c1
FROM dbo.Sort AS S
ORDER BY
S.c1 ASC
OFFSET 1000 * 1000 - 1 ROWS
FETCH FIRST 1 ROW ONLY
OPTION
(
RECOMPILE,
MAXDOP 1
);
This returns just the last row to minimize the time to display results on the client. A typical execution plan shows sorting took 701ms:

To compare this to sorting without the fast key optimization, we need undocumented trace flag 7490 (global only).
DBCC TRACEON (7490, -1);
Running the same sorting test again:


The same sort now takes 843ms—an increase of 142ms or about 20%.
Remember to re-enable the fast key optimization after testing:
DBCC TRACEOFF (7490, -1);
Conclusion
Row mode sorting has a useful optimization for a limited set of simple data types. Wherever possible, you should look to use the supported types for sort keys. These are repeated below for convenience:
- tinyint, smallint, integer
- money, smallmoney
- datetime, smalldatetime
- float (NOT NULL only)
The fast key optimization is not limited to Top N Sorts as shown in the example. Use the sort_statistics_tracing extended event to monitor the use of this feature.
No comments:
Post a Comment
All comments are reviewed before publication.