There is much more to query tuning than reducing logical reads and adding covering nonclustered indexes. Query tuning is not complete as soon as the query returns results quickly in the development or test environments.
In production, your query will compete for memory, CPU, locks, I/O, and other resources on the server. Today’s post looks at some tuning considerations that are often overlooked, and shows how deep internals knowledge can help you write better T-SQL.
Example data
We are going to need three tables today, each of which is structured like this:
Each table has 50,000 rows made up of an integer id column and a padding column containing 3,999 characters in every row.
The only difference between the three tables is in the type of the padding column:
- The first table uses
char(3999) - The second uses
varchar(max) - The third uses the deprecated
texttype.
A script to create a database with the three tables, and load the sample data follows:
USE master;
GO
IF DB_ID('SortTest') IS NOT NULL
BEGIN
DROP DATABASE SortTest;
END;
GO
CREATE DATABASE SortTest
COLLATE Latin1_General_BIN;
GO
ALTER DATABASE SortTest
MODIFY FILE
(
NAME = 'SortTest',
SIZE = 3GB,
MAXSIZE = 3GB
);
GO
ALTER DATABASE SortTest
MODIFY FILE
(
NAME = 'SortTest_log',
SIZE = 256MB,
MAXSIZE = 1GB,
FILEGROWTH = 128MB
);
GO
ALTER DATABASE SortTest
SET ALLOW_SNAPSHOT_ISOLATION OFF;
ALTER DATABASE SortTest
SET AUTO_CLOSE OFF,
AUTO_CREATE_STATISTICS ON,
AUTO_SHRINK OFF,
AUTO_UPDATE_STATISTICS ON,
AUTO_UPDATE_STATISTICS_ASYNC ON,
PARAMETERIZATION SIMPLE,
READ_COMMITTED_SNAPSHOT OFF,
MULTI_USER,
RECOVERY SIMPLE;
GO
USE SortTest;
GO
CREATE TABLE dbo.TestCHAR
(
id integer IDENTITY (1,1) NOT NULL,
padding char(3999) NOT NULL,
CONSTRAINT [PK dbo.TestCHAR (id)]
PRIMARY KEY CLUSTERED (id),
);
CREATE TABLE dbo.TestMAX
(
id integer IDENTITY (1,1) NOT NULL,
padding varchar(max) NOT NULL,
CONSTRAINT [PK dbo.TestMAX (id)]
PRIMARY KEY CLUSTERED (id),
);
CREATE TABLE dbo.TestTEXT
(
id integer IDENTITY (1,1) NOT NULL,
padding text NOT NULL,
CONSTRAINT [PK dbo.TestTEXT (id)]
PRIMARY KEY CLUSTERED (id),
);
-- =============
-- Load TestCHAR
-- =============
INSERT dbo.TestCHAR
WITH (TABLOCKX)
(padding)
SELECT
padding = REPLICATE(CHAR(65 + ([Data].n % 26)), 3999)
FROM
(
SELECT TOP (50000)
n = ROW_NUMBER() OVER (
ORDER BY (SELECT 0)) - 1
FROM master.sys.columns AS C1
CROSS JOIN master.sys.columns AS C2
CROSS JOIN master.sys.columns AS C3
ORDER BY
n ASC
) AS [Data]
ORDER BY
[Data].n ASC;
-- ============
-- Load TestMAX
-- ============
INSERT dbo.TestMAX
WITH (TABLOCKX)
(padding)
SELECT
CONVERT(varchar(max), padding)
FROM dbo.TestCHAR
ORDER BY
id;
-- =============
-- Load TestTEXT
-- =============
INSERT dbo.TestTEXT
WITH (TABLOCKX)
(padding)
SELECT
CONVERT(text, padding)
FROM dbo.TestCHAR
ORDER BY
id;
-- ==========
-- Space used
-- ==========
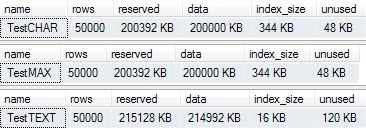
EXECUTE sys.sp_spaceused @objname = N'dbo.TestCHAR';
EXECUTE sys.sp_spaceused @objname = N'dbo.TestMAX';
EXECUTE sys.sp_spaceused @objname = N'dbo.TestTEXT';
CHECKPOINT;
The space allocated to each table is shown in the output:
Task
To illustrate the points I want to make today, the example task we are going to set ourselves is to return a random set of 150 rows from each table.
The basic shape of the test query is the same for each of the three test tables:
SELECT TOP (150)
T.id,
T.padding
FROM dbo.Test AS T
ORDER BY
NEWID()
OPTION
(MAXDOP 1);
Test 1 — char(3999)
Running the template query shown above using the TestCHAR table as the target, the query takes around 5 seconds to return its results. This seems a bit slow, considering that the table only has 50,000 rows.
Working on the assumption that generating a GUID for each row is a CPU-intensive operation, we might try enabling parallelism to see if that speeds up the response time.
Running the query again without the MAXDOP 1 hint on a machine with eight logical processors, the query now takes 10 seconds to execute — twice as long as when run serially.
Rather than attempting further guesses at the cause of the slowness, let’s go back to serial execution and add some monitoring.
The script below monitors STATISTICS IO output and the amount of tempdb used by the test query. We will also run a Profiler trace to capture any warnings generated during query execution.
DECLARE
@read bigint,
@write bigint;
SELECT
@read = SUM(num_of_bytes_read),
@write = SUM(num_of_bytes_written)
FROM tempdb.sys.database_files AS DBF
JOIN sys.dm_io_virtual_file_stats(2, NULL) AS FS
ON FS.[file_id] = DBF.[file_id]
WHERE
DBF.[type_desc] = 'ROWS';
SET STATISTICS IO ON;
SELECT TOP (150)
TC.id,
TC.padding
FROM dbo.TestCHAR AS TC
ORDER BY
NEWID()
OPTION
(MAXDOP 1);
SET STATISTICS IO OFF;
SELECT
tempdb_read_MB = (SUM(num_of_bytes_read) - @read) / 1024. / 1024.,
tempdb_write_MB = (SUM(num_of_bytes_written) - @write) / 1024. / 1024.,
internal_use_MB =
(
SELECT
internal_objects_alloc_page_count / 128.0
FROM sys.dm_db_task_space_usage
WHERE
session_id = @@SPID
)
FROM tempdb.sys.database_files AS DBF
JOIN sys.dm_io_virtual_file_stats(2, NULL) AS FS
ON FS.[file_id] = DBF.[file_id]
WHERE
DBF.[type_desc] = 'ROWS';
Let’s take a closer look at the statistics output and execution plan:

Following the flow of the data from right to left, we see the expected 50,000 rows emerging from the Clustered Index Scan, with a total estimated size of around 191MB.
The Compute Scalar adds a column containing a random GUID (generated by the NEWID() function call) for each row. With this extra column, the size of the data arriving at the Sort operator is estimated to be 192MB.
Sort is a blocking operator — it has to examine all of the rows on its input before it can produce its first row of output (the last row received might sort first).
This means that Sort requires a memory grant — memory allocated for the query’s use by SQL Server just before execution starts.
In this case, the Sort is the only memory-consuming operator in the plan, so it has access to the full 243MB (248,696KB) of memory reserved by SQL Server for this query execution.
In spite of the large memory grant, the Profiler trace shows a Sort Warning event, indicating that the sort ran out of memory.
The tempdb usage monitor shows that 195MB of tempdb space was used –-- all for system use. The 195MB represents physical write activity on tempdb, because SQL Server strictly enforces memory grants. A query cannot ‘cheat’ and effectively gain extra memory by spilling to tempdb pages that reside in memory.
Anyway, the key point here is that it takes a while to write 195MB to disk, and this is the main reason that the query takes 5 seconds overall.
If you are wondering why using parallelism made the problem worse, consider that eight threads of execution result in eight concurrent partial sorts, each receiving one eighth of the memory grant. The eight sorts all spilled to tempdb, resulting in inefficiencies as the spilled sorts competed for disk resources.
char(3999) performance summary:
- 5 seconds elapsed time
- 243MB memory grant
- 195MB tempdb usage
- 192MB estimated sort set
- 25,043 logical reads
- Sort Warning
Test 2 — varchar(max)
We’ll now run exactly the same test (with the additional monitoring) on the table using a varchar(max) padding column:
DECLARE
@read bigint,
@write bigint;
SELECT
@read = SUM(num_of_bytes_read),
@write = SUM(num_of_bytes_written)
FROM tempdb.sys.database_files AS DBF
JOIN sys.dm_io_virtual_file_stats(2, NULL) AS FS
ON FS.[file_id] = DBF.[file_id]
WHERE
DBF.[type_desc] = 'ROWS';
SET STATISTICS IO ON;
SELECT TOP (150)
TM.id,
TM.padding
FROM dbo.TestMAX AS TM
ORDER BY
NEWID()
OPTION
(MAXDOP 1);
SET STATISTICS IO OFF;
SELECT
tempdb_read_MB = (SUM(num_of_bytes_read) - @read) / 1024. / 1024.,
tempdb_write_MB = (SUM(num_of_bytes_written) - @write) / 1024. / 1024.,
internal_use_MB =
(
SELECT
internal_objects_alloc_page_count / 128.0
FROM sys.dm_db_task_space_usage
WHERE
session_id = @@SPID
)
FROM tempdb.sys.database_files AS DBF
JOIN sys.dm_io_virtual_file_stats(2, NULL) AS FS
ON FS.[file_id] = DBF.[file_id]
WHERE
DBF.[type_desc] = 'ROWS';
The results are:

This time the query takes around 8 seconds to complete (3 seconds longer than Test 1). Notice that the estimated row and data sizes are very slightly larger, and the overall memory grant has also increased very slightly to 245MB.
The most marked difference is in the amount of tempdb space used. This query wrote almost 391MB of sort run data to the physical tempdb file.
Don’t draw any general conclusions about varchar(max) versus char from this — I chose the length of the data specifically to expose this edge case. In most cases, varchar(max) performs very similarly to char, I just wanted to make test 2 a bit more exciting.
MAX performance summary:
- 8 seconds elapsed time
- 245MB memory grant
- 391MB tempdb usage
- 193MB estimated sort set
- 25,043 logical reads
- Sort warning
Test 3 — text
The same test again, but using the deprecated text data type for the padding column:
DECLARE
@read bigint,
@write bigint;
SELECT
@read = SUM(num_of_bytes_read),
@write = SUM(num_of_bytes_written)
FROM tempdb.sys.database_files AS DBF
JOIN sys.dm_io_virtual_file_stats(2, NULL) AS FS
ON FS.[file_id] = DBF.[file_id]
WHERE
DBF.[type_desc] = 'ROWS';
SET STATISTICS IO ON;
SELECT TOP (150)
TT.id,
TT.padding
FROM dbo.TestTEXT AS TT
ORDER BY
NEWID()
OPTION
(MAXDOP 1);
SET STATISTICS IO OFF;
SELECT
tempdb_read_MB = (SUM(num_of_bytes_read) - @read) / 1024. / 1024.,
tempdb_write_MB = (SUM(num_of_bytes_written) - @write) / 1024. / 1024.,
internal_use_MB =
(
SELECT
internal_objects_alloc_page_count / 128.0
FROM sys.dm_db_task_space_usage
WHERE
session_id = @@SPID
)
FROM tempdb.sys.database_files AS DBF
JOIN sys.dm_io_virtual_file_stats(2, NULL) AS FS
ON FS.[file_id] = DBF.[file_id]
WHERE
DBF.[type_desc] = 'ROWS';
The output:

This time the query runs in 500ms. Looking at the metrics we have been checking so far, it’s not hard to understand why:
text performance summary:
- 0.5 seconds elapsed time
- 9MB memory grant
- 5MB tempdb usage
- 5MB estimated sort set
- 207 logical reads
- 596 LOB logical reads
- Sort warning
SQL Server still underestimates the memory needed to perform the sorting operation, but the size of the data to sort is so much smaller (5MB versus 193MB previously) that the spilled sort doesn’t matter very much.
Why is the data size so much smaller? The query still produces the correct results — including the large amount of data held in the padding column — so what magic is being performed here?
text versus max Storage
By default, text data is stored off-row in separate LOB pages. This explains why this is the first query we have seen that records lob logical reads in its STATISTICS IO output.
You may recall from I see no LOBs! that LOB data leaves an in-row pointer to the separate storage structure holding the LOB data.
SQL Server can see that the full LOB value is not required by the plan until results are returned, so instead of passing the full LOB value down the plan from the Clustered Index Scan, it passes the in-row pointer instead.
SQL Server estimates that each row coming from the scan will be 79 bytes long: 11 bytes for row overhead, 4 bytes for the integer id column, and 64 bytes for the LOB pointer (in fact the pointer is normally rather smaller, but the details of that don’t really matter right now).
So this query is much more efficient because it is sorting a very much smaller data set. SQL Server delays retrieving the LOB data until after the Sort starts producing its 150 rows.
The question that arises at this point is: Why doesn’t SQL Server use the same trick when the padding column is defined as varchar(max)?
The answer is connected with the fact that if the actual size of the varchar(max) data is 8000 bytes or less, it is usually stored in-row in exactly the same way as for a varchar(8000) column. Data in a varchar(max) column only moves off-row into LOB storage when it exceeds 8000 bytes.
The default behaviour of the text type is to be stored off-row by default, unless the text in row’table option is set suitably and there is room on the page.
There is an analogous (but opposite) setting to control the storage of MAX data – the large value types out of rowtable option. By enabling this option for a table, max data will be stored off-row (in a LOB structure) instead of in-row.
The documenation has good coverage of both options in the topic In Row Data.
The MAXOOR Table
The essential difference, then, is that max defaults to in-row storage, and text defaults to off-row (LOB) storage.
You might be thinking that we could get the same benefits seen for the text data type by storing the varchar(max) values off row, so let’s look at that option.
This next script creates a fourth table, with the varchar(max) data stored off-row in LOB pages:
CREATE TABLE dbo.TestMAXOOR
(
id integer IDENTITY (1,1) NOT NULL,
padding varchar(MAX) NOT NULL,
CONSTRAINT [PK dbo.TestMAXOOR (id)]
PRIMARY KEY CLUSTERED (id),
);
EXECUTE sys.sp_tableoption
@TableNamePattern = N'dbo.TestMAXOOR',
@OptionName = 'large value types out of row',
@OptionValue = 'true';
SELECT
large_value_types_out_of_row
FROM sys.tables
WHERE
[schema_id] = SCHEMA_ID(N'dbo')
AND [name] = N'TestMAXOOR';
INSERT dbo.TestMAXOOR
WITH (TABLOCKX)
(padding)
SELECT
SPACE(0)
FROM dbo.TestCHAR
ORDER BY
id;
UPDATE TM
WITH (TABLOCK)
SET padding.WRITE (TC.padding, NULL, NULL)
FROM dbo.TestMAXOOR AS TM
JOIN dbo.TestCHAR AS TC
ON TC.id = TM.id;
EXECUTE sys.sp_spaceused
@objname = 'dbo.TestMAXOOR';
CHECKPOINT;
Test 4 — MAX out of row
We can now re-run our test on the MAXOOR (MAX out of row) table:
DECLARE
@read bigint,
@write bigint;
SELECT
@read = SUM(num_of_bytes_read),
@write = SUM(num_of_bytes_written)
FROM tempdb.sys.database_files AS DBF
JOIN sys.dm_io_virtual_file_stats(2, NULL) AS FS
ON FS.[file_id] = DBF.[file_id]
WHERE
DBF.[type_desc] = 'ROWS';
SET STATISTICS IO ON;
SELECT TOP (150)
TM.id,
TM.padding
FROM dbo.TestMAXOOR AS TM
ORDER BY
NEWID()
OPTION
(MAXDOP 1);
SET STATISTICS IO OFF;
SELECT
tempdb_read_MB = (SUM(num_of_bytes_read) - @read) / 1024. / 1024.,
tempdb_write_MB = (SUM(num_of_bytes_written) - @write) / 1024. / 1024.,
internal_use_MB =
(
SELECT
internal_objects_alloc_page_count / 128.0
FROM sys.dm_db_task_space_usage
WHERE
session_id = @@SPID
)
FROM tempdb.sys.database_files AS DBF
JOIN sys.dm_io_virtual_file_stats(2, NULL) AS FS
ON FS.[file_id] = DBF.[file_id]
WHERE
DBF.[type_desc] = 'ROWS';
Results:

MAX out of row performance summary:
- 0.3 seconds elapsed time
- 245MB memory grant
- 0MB tempdb usage
- 193MB estimated sort set
- 207 logical reads
- 446 LOB logical reads
- No sort warning
The query runs very quickly, slightly faster than Test 3, and without spilling the Sort to tempdb. There is no sort warning in the trace, and the monitoring query shows zero tempdb usage by this query.
SQL Server is passing the in-row pointer structure down the plan and only looking up the LOB value on the output side of the sort.
The Hidden Problem
There is still a huge problem with this query though: It requires a 245MB memory grant. No wonder the sort doesn’t spill to tempdb now — 245MB is about 20 times more memory than this query actually requires to sort 50,000 records containing LOB data pointers. Notice that the estimated row and data sizes in the plan are the same as in test 2 (where the max data was stored in-row).
The optimizer assumes that max data is stored in-row, regardless of the large value types out of row setting. Why? Because this option is dynamic — changing it does not immediately force all max data in the table in-row or off-row, only when data is added or actually changed.
SQL Server does not keep statistics to show how much max or text data is currently in-row, and how much is stored in LOB pages. This is a limitation that I hope to be addressed in a future version.
Why should we worry about this?
Excessive memory grants reduce concurrency and may result in queries waiting on the RESOURCE_SEMAPHORE wait type while they wait for memory they do not need.
245MB is an awful lot of memory, especially on 32-bit versions where memory grants cannot use AWE-mapped memory.
Even on a 64-bit server with plenty of memory, do you really want a single query to consume 0.25GB of memory unnecessarily? That’s 32,000 8KB pages that might be put to much better use for other purposes.
The Solution
The answer is not to use the text data type for the padding column.
That solution happens to have better performance characteristics for this specific query, but it still results in a spilled sort, and it is hard to recommend the use of a data type which is scheduled for removal.
I hope it is clear that the fundamental problem here is that SQL Server sorts the whole set arriving at a Sort operator. It is not efficient to sort the whole table in memory just to return 150 rows in a random order.
The text example was more efficient because it dramatically reduced the size of the set that needed to be sorted.
We can do the same thing by selecting 150 unique keys from the table at random (sorting by NEWID() for example) and only then retrieving the large padding column values for only the 150 rows we need.
The following script implements that idea for all four tables:
SET STATISTICS IO ON;
WITH
TestTable AS
(
SELECT *
FROM dbo.TestCHAR
),
TopKeys AS
(
SELECT TOP (150) id
FROM TestTable
ORDER BY NEWID()
)
SELECT
T1.id,
T1.padding
FROM TestTable AS T1
WHERE
T1.id = ANY (SELECT id FROM TopKeys)
OPTION
(MAXDOP 1, FAST 1);
WITH
TestTable AS
(
SELECT *
FROM dbo.TestMAX
),
TopKeys AS
(
SELECT TOP (150) id
FROM TestTable
ORDER BY NEWID()
)
SELECT
T1.id,
T1.padding
FROM TestTable AS T1
WHERE
T1.id = ANY (SELECT id FROM TopKeys)
OPTION
(MAXDOP 1, FAST 1);
WITH
TestTable AS
(
SELECT *
FROM dbo.TestTEXT
),
TopKeys AS
(
SELECT TOP (150) id
FROM TestTable
ORDER BY NEWID()
)
SELECT
T1.id,
T1.padding
FROM TestTable AS T1
WHERE
T1.id = ANY (SELECT id FROM TopKeys)
OPTION
(MAXDOP 1, FAST 1);
WITH
TestTable AS
(
SELECT *
FROM dbo.TestMAXOOR
),
TopKeys AS
(
SELECT TOP (150) id
FROM TestTable
ORDER BY NEWID()
)
SELECT
T1.id,
T1.padding
FROM TestTable AS T1
WHERE
T1.id = ANY (SELECT id FROM TopKeys)
OPTION
(MAXDOP 1, FAST 1);
SET STATISTICS IO OFF;
All four queries now return results in much less than a second, with memory grants between 6 and 12MB, and without spilling to tempdb. The FAST 1 hint is there to help ensure the optimizer chooses the desired lookup plan.
The small remaining inefficiency is in reading the id column values from the clustered primary key index. As a clustered index, it contains all the in-row data at its leaf.
The char and varchar(max) tables store the padding column in-row, so id values are separated by a 3999-character column, plus row overhead.
The text and max out-of-row tables store the padding values off-row, so id values in the clustered index leaf are separated by the much-smaller off-row pointer structure. This difference is reflected in the number of logical page reads performed by the four queries:
Table 'TestCHAR' logical reads 25511 lob logical reads 0
Table 'TestMAX' logical reads 25511 lob logical reads 0
Table 'TestTEXT' logical reads 412 lob logical reads 597
Table 'TestMAXOOR' logical reads 413 lob logical reads 446
We can increase the density of the id values by creating a separate nonclustered index on the id column only. This is the same key as the clustered index, but the nonclustered index will not ‘include’ the rest of the in-row column data.
CREATE UNIQUE NONCLUSTERED INDEX uq1 ON dbo.TestCHAR (id);
CREATE UNIQUE NONCLUSTERED INDEX uq1 ON dbo.TestMAX (id);
CREATE UNIQUE NONCLUSTERED INDEX uq1 ON dbo.TestTEXT (id);
CREATE UNIQUE NONCLUSTERED INDEX uq1 ON dbo.TestMAXOOR (id);
The four queries can now use the very dense nonclustered index to quickly read the id values, sort them by NEWID(), select the 150 we want, and then look up the padding data.
The logical reads with the new indexes in place are:
Table 'TestCHAR' logical reads 835 lob logical reads 0
Table 'TestMAX' logical reads 835 lob logical reads 0
Table 'TestTEXT' logical reads 686 lob logical reads 597
Table 'TestMAXOOR' logical reads 686 lob logical reads 448
With the new index, all four queries use the same query plan (without hints):

Performance Summary:
- 0.3 seconds elapsed time
- 6MB memory grant
- 0MB tempdb usage
- 1MB sort set
- 835 logical reads (
char,maxin row) - 686 logical reads (
text,maxout of row) - 597 lob logical reads (
text) - 448 lob logical reads (
maxout of row) - No sort warning
I’ll leave it as an exercise for the reader to work out why trying to eliminate the Key Lookup by adding the padding column to the new nonclustered indexes would be a daft idea.
Conclusion
This post is not about tuning queries that access columns containing big strings. It isn’t about the internal differences between text and max data types either. It isn’t even about the cool use of UPDATE .WRITE used in the MAXOOR table load. No, this post is about something else:
Many experienced SQL Server professionals might not have tuned our starting example query at all.
Five seconds execution time is not that bad, and the original query plan looks reasonable at first glance. Perhaps the NEWID() function would have been blamed for ‘just being slow’, who knows. The execution time is not obviously an issue, unless your users expect sub-second responses perhaps.
On the other hand, using 250MB of memory and writing 200MB to tempdb might well be a concern. If ten sessions ran that query at the same time in production that’s 2.5GB of memory usage and 2GB hitting tempdb.
If you are running SQL Server 2012 or later, you can avoid the spills to tempdb in these examples by enabling documented trace flag 7470. This corrects an oversight in the sort memory algorithm, but you will still be left using much more memory than necessary.
Naturally, not all queries can be rewritten to avoid large memory grants and sort spills using the key-lookup technique in this post, but that’s not the point either.
The point of this post is that a basic understanding of execution plans is not enough. Tuning for logical reads and adding covering indexes is not enough.
If you want to produce high-quality, scalable T-SQL that won’t get you paged as soon as it hits production, you need a deep understanding of execution plans, and as much accurate, deep knowledge about SQL Server as you can lay your hands on.
The advanced database professional has a wide range of tools to use in writing queries that perform well in a range of circumstances.
By the way, the examples in this post were written for SQL Server 2008 or later. They will run on 2005 and demonstrate the same principles, but you won’t get the same figures I did because 2005 had a rather nasty bug in the Top N Sort operator. Fair warning: if you do decide to run the scripts on a 2005 instance (particularly the parallel query) do it before you head out for lunch.
© Paul White
email: SQLkiwi@gmail.com
twitter: @SQL_Kiwi
No comments:
Post a Comment
All comments are reviewed before publication.