A seek can contain one or more seek predicates, each of which can either identify (at most) one row in a unique index (a singleton lookup) or a range of values (a range scan).
When looking at an execution plan, we often need to look at the details of the seek operator in the Properties window to see how many operations it is performing, and what type of operation each one is.
As seen in the first post of this mini-series, When is a Seek not a Seek? the number of hidden seeking operations can have an appreciable impact on performance.
Measuring Seeks and Scans
I mentioned in So…is it a Seek or a Scan? that there is no way to tell from a graphical query plan whether you are seeing a singleton lookup or a range scan.
You can work it out — if you happen to know that the index is defined as unique and the seek predicate is an equality comparison, but there’s no separate property that says ‘singleton lookup’ or ‘range scan’.
That is a shame. If I had my way, the execution plan would show different icons for range scans and singleton lookups, perhaps also indicating whether the operation was one or more of those operations under the covers.
There another way to measure how many seeks of either type are occurring in your system, or for a particular query – using a couple of dynamic management views (DMVs):
Index Usage Stats
The index usage stats DMV contains counts of index operations from the perspective of the Query Executor (QE). This is the SQL Server component responsible for executing the query plan.
It has three columns that are of particular interest to us:
| name | description |
|---|---|
| user_seeks | Number of times an Index Seek operator appears in an executed plan. |
| user_scans | Number of times a Table Scan or Index Scan operator appears in an executed plan. |
| user_lookups | Number of times an RID or Key Lookup operator appears in an executed plan. |
The way these counters are incremented is not entirely intuitive:
- An operator is counted once per plan execution.
- Generating an estimated plan does not affect the totals.
- An Index Seek that executes 10,000 times in a single plan execution still only adds 1 to the count of user seeks.
- An operator is counted even if it is not executed at all.
I demonstrate of each of these points later in this post.
Index Operational Stats
The index operational stats DMV contains counts of index and table operations from the perspective of the Storage Engine (SE).
It contains a wealth of interesting information, but the two columns of interest to us right now are:
| name | description |
|---|---|
| range_scan_count | Number of range scans (including unrestricted full scans) on a heap or index structure. |
| singleton_lookup_count | Number of singleton lookups in a heap or index structure. |
This DMV counts each storage engine operation, making the counters perhaps more intuitive:
- 10,000 singleton lookups will add 10,000 to the singleton lookup count column
- A table scan that is executed 5 times will add 5 to the range scan count.
Test Rig
To explore the behaviour of seeks and scans in detail, we will need to create a test environment.
The scripts presented here are best run on SQL Server 2008 Developer Edition or later, but the majority of the tests will work just fine on SQL Server 2005. A couple of tests use partitioning, but these will be skipped if you are not running an Enterprise-equivalent SKU.
First up we need a database:
USE master;
GO
IF DB_ID('ScansAndSeeks') IS NOT NULL
BEGIN
DROP DATABASE ScansAndSeeks;
END;
GO
CREATE DATABASE ScansAndSeeks;
GO
USE ScansAndSeeks;
GO
ALTER DATABASE ScansAndSeeks
SET ALLOW_SNAPSHOT_ISOLATION OFF;
ALTER DATABASE ScansAndSeeks
SET AUTO_CLOSE OFF,
AUTO_SHRINK OFF,
AUTO_CREATE_STATISTICS OFF,
AUTO_UPDATE_STATISTICS OFF,
PARAMETERIZATION SIMPLE,
READ_COMMITTED_SNAPSHOT OFF,
RESTRICTED_USER;
Several database options are set in particular ways to ensure we get meaningful and reproducible results from the DMVs. In particular, the options to auto-create and update statistics are disabled.
We will also need three stored procedures. The first of these creates a test table (which may or may not be partitioned). The table is pretty much the same one we used last time:

The Example table has 100 rows, with both the key_col and data columns containing the same values: integers from 1 to 100 inclusive.
The table is a heap, with a nonclustered primary key on key_col, and a non-clustered non-unique index on the data column.
The only reason I have used a heap here, rather than a clustered table, is so I can demonstrate a seek on a heap later on.
The table has an extra column (not shown because I am too lazy to update the diagram from yesterday) called padding. This a char(100) column that just contains 100 spaces in every row. It is there to discourage SQL Server from choosing a table scan over an index seek with RID lookup in one of the tests.
Test Reset Procedure
The first stored procedure is called ResetTest:
CREATE PROCEDURE dbo.ResetTest
@Partitioned bit = 'false'
AS
BEGIN
SET NOCOUNT ON;
IF OBJECT_ID(N'dbo.Example', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Example;
END;
-- Test table is a heap
-- Non-clustered primary key on 'key_col'
CREATE TABLE dbo.Example
(
key_col integer NOT NULL,
[data] integer NOT NULL,
padding char(100) NOT NULL
DEFAULT SPACE(100),
CONSTRAINT [PK dbo.Example key_col]
PRIMARY KEY NONCLUSTERED (key_col)
);
IF @Partitioned = 'true'
BEGIN
-- Enterprise, Trial, or Developer
-- required for partitioning tests
IF SERVERPROPERTY('EngineEdition') = 3
BEGIN
EXECUTE
(
'
DROP TABLE dbo.Example;
IF EXISTS
(
SELECT 1
FROM sys.partition_schemes
WHERE name = N''PS''
)
BEGIN
DROP PARTITION SCHEME PS;
END;
IF EXISTS
(
SELECT 1
FROM sys.partition_functions
WHERE name = N''PF''
)
BEGIN
DROP PARTITION FUNCTION PF;
END;
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES (20, 40, 60, 80, 100);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
CREATE TABLE dbo.Example
(
key_col integer NOT NULL,
data integer NOT NULL,
padding char(100) NOT NULL
DEFAULT SPACE(100),
CONSTRAINT [PK dbo.Example key_col]
PRIMARY KEY NONCLUSTERED (key_col)
)
ON PS (key_col);'
);
END
ELSE
BEGIN
RAISERROR('Invalid SKU for partition test', 16, 1);
RETURN;
END;
END
;
-- Non-unique non-clustered index on the 'data' column
CREATE NONCLUSTERED INDEX
[IX dbo.Example data]
ON dbo.Example ([data]);
-- Add 100 rows
INSERT dbo.Example
WITH (TABLOCKX)
(
key_col,
[data]
)
SELECT
key_col = V.number,
[data] = V.number
FROM master.dbo.spt_values AS V
WHERE
V.[type] = N'P'
AND V.number BETWEEN 1 AND 100;
END;
GO
Show Stats Procedure
The second stored procedure, ShowStats, displays information from the Index Usage Stats and Index Operational Stats DMVs:
CREATE PROCEDURE dbo.ShowStats
@Partitioned bit = 'false'
AS
BEGIN
-- Index Usage Stats DMV (QE)
SELECT
index_name = ISNULL(I.[name], I.[type_desc]),
scans = IUS.user_scans,
seeks = IUS.user_seeks,
lookups = IUS.user_lookups
FROM sys.dm_db_index_usage_stats AS IUS
JOIN sys.indexes AS I
ON I.[object_id] = IUS.[object_id]
AND I.index_id = IUS.index_id
WHERE
IUS.database_id = DB_ID(N'ScansAndSeeks')
AND IUS.[object_id] = OBJECT_ID(N'dbo.Example', N'U')
ORDER BY
I.index_id;
-- Index Operational Stats DMV (SE)
IF @Partitioned = 'true'
BEGIN
SELECT
index_name = ISNULL(I.[name], I.[type_desc]),
[partitions] = COUNT(IOS.partition_number),
range_scans = SUM(IOS.range_scan_count),
single_lookups = SUM(IOS.singleton_lookup_count)
FROM sys.dm_db_index_operational_stats
(
DB_ID(N'ScansAndSeeks'),
OBJECT_ID(N'dbo.Example', N'U'),
NULL,
NULL
) AS IOS
JOIN sys.indexes AS I
ON I.[object_id] = IOS.[object_id]
AND I.index_id = IOS.index_id
GROUP BY
I.index_id, -- Key
I.[name],
I.[type_desc]
ORDER BY
I.index_id;
END
ELSE
BEGIN
SELECT
index_name = ISNULL(I.[name], I.[type_desc]),
range_scans = SUM(IOS.range_scan_count),
single_lookups = SUM(IOS.singleton_lookup_count)
FROM sys.dm_db_index_operational_stats
(
DB_ID(N'ScansAndSeeks'),
OBJECT_ID(N'dbo.Example', N'U'),
NULL,
NULL
) AS IOS
JOIN sys.indexes AS I
ON I.[object_id] = IOS.[object_id]
AND I.index_id = IOS.index_id
GROUP BY
I.index_id, -- Key
I.[name],
I.[type_desc]
ORDER BY
I.index_id;
END;
END;
GO
Run Test Procedure
The final stored procedure, RunTest, executes a query written against the example table:
CREATE PROCEDURE dbo.RunTest
@SQL varchar(8000),
@Partitioned bit = 'false'
AS
BEGIN
-- No execution plan yet
SET STATISTICS XML OFF;
-- Reset the test environment
EXECUTE dbo.ResetTest @Partitioned;
-- Previous call will throw an error if a partitioned
-- test was requested, but SKU does not support it
IF @@ERROR = 0
BEGIN
-- IO statistics and plan on
SET STATISTICS XML, IO ON;
-- Test statement
EXECUTE (@SQL);
-- Plan and IO statistics off
SET STATISTICS XML, IO OFF;
EXECUTE dbo.ShowStats @Partitioned;
END;
END;
GO
The Tests
The first test is an unrestricted scan of the heap table:
EXECUTE dbo.RunTest
@SQL = 'SELECT * FROM Example';
The results are:

The uppermost result set comes from the Index Usage Stats DMV, so it is the Query Executor’s (QE) view of things. The lower result is from Index Operational Stats, which shows statistics derived from the actions taken by the Storage Engine (SE).
QE reports 1 scan operation on the heap. SE reports a single range scan.
Unique Index Equality Seek
Let’s try a single-value equality seek on a unique index next:
EXECUTE dbo.RunTest
@SQL = 'SELECT key_col
FROM Example
WHERE key_col = 32';

This time we see a single seek on the non-clustered primary key from QE, and one singleton lookup on the same index by the SE.
Non-Unique Index Equality Seek
Now for a single-value equality seek on the non-unique non-clustered index:
EXECUTE dbo.RunTest
@SQL = 'SELECT data
FROM Example
WHERE data = 32';

QE shows a single seek on the nonclustered non-unique index, but SE shows a single range scan on that index — not the singleton lookup we saw in the previous test.
That makes sense because we know that only a single-value seek into a unique index is a singleton seek. A single-value seek into a non-unique index might retrieve any number of rows, if you think about it.
Multiple Values
The next query is similar to the IN list example seen in the first post in this series, but it is written using OR just for variety:
EXECUTE dbo.RunTest
@SQL = 'SELECT data
FROM Example
WHERE data = 32
OR data = 33';

The plan looks the same, and there’s no difference in the statistics recorded by QE, but SE shows two range scans. Again, these are range scans because we are looking for two values in the data column, which is covered by a non-unique index.
I’ve added a snippet from the Properties window to show that the query plan does show two seek predicates, not just one.
BETWEEN
Now let’s rewrite the query using BETWEEN:
EXECUTE dbo.RunTest
@SQL = 'SELECT data
FROM Example
WHERE data BETWEEN 32 AND 33';

The seek operator only has one predicate now — it’s just a single range scan from 32 to 33 in the index, as the SE output shows.
Four values
For the next test, we will look up four values in the key_col column:
EXECUTE dbo.RunTest
@SQL = 'SELECT key_col
FROM Example
WHERE key_col IN (2,4,6,8)';

Just a single seek on the PK from the Query Executor, but four singleton lookups reported by the Storage Engine, and four seek predicates in the Properties window.
RID Lookups
On to a more complex example:
EXECUTE dbo.RunTest
@SQL = 'SELECT * FROM Example
WITH (INDEX([PK dbo.Example key_col]))
WHERE key_col BETWEEN 1 AND 8';

This time we are forcing use of the non-clustered primary key to return eight rows. The index is not covering for this query, so the query plan includes an RID Lookup into the heap to fetch the data and padding columns.
The QE reports a seek on the PK and a lookup on the heap.
The SE reports a single range scan on the PK (to find key_col values between 1 and 8), and eight singleton lookups on the heap.
Remember that a bookmark lookup (RID or Key) is a seek to a single value in a ‘unique index’ — it finds a row in the heap or clustered index from a unique RID or clustering key. That is why lookups are always singleton lookups, not range scans.
Operator not executed
Our next example shows what happens when a query plan operator is not executed at all:
EXECUTE dbo.RunTest
@SQL = 'SELECT key_col
FROM Example
WHERE key_col = 8
AND @@TRANCOUNT < 0';
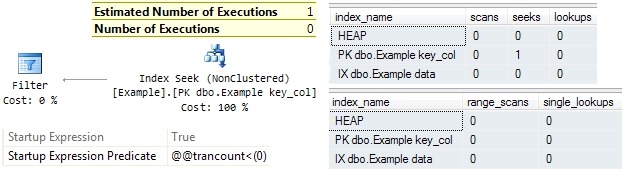
The Filter operator has a start-up predicate which is always false (if your @@TRANCOUNT is less than zero, call support immediately).
The index seek is never executed, but QE still records a single seek against the PK because the operator appears once in an executed plan. The SE output shows no activity at all.
Seek on a Heap I
This next example is 2008 and above only, I’m afraid:
EXECUTE dbo.RunTest
@SQL = 'SELECT *
FROM Example
WHERE key_col BETWEEN 1 AND 30',
@Partitioned = 'true';

This is the first example to use a partitioned table. QE reports a single seek on the heap (yes – a seek on a heap), and the SE reports two range scans on the heap.
SQL Server knows (from the partitioning definition) that it only needs to look at partitions 1 and 2 to find all the rows where key_col is between 1 and 30. The engine seeks to find the two partitions, and performs a range scan seek on each partition.
Seek on a Heap II
The final example is another seek on a heap. Try to work out the test output for the query before running it!
EXECUTE dbo.RunTest
@SQL = 'SELECT TOP (2) WITH TIES *
FROM Example
WHERE key_col BETWEEN 1 AND 50
ORDER BY $PARTITION.PF(key_col) DESC',
@Partitioned = 'true';

Notice the lack of an explicit Sort operator in the query plan to enforce the ORDER BY clause, and the BACKWARD range scan.
Full test script with additional examples on GitHub.
© Paul White
email: SQLkiwi@gmail.com
twitter: @SQL_Kiwi
Nice post thank you Tania
ReplyDelete