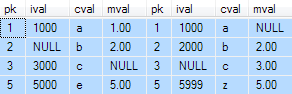
The diagram below shows two data sets, with differences highlighted:

To find changed rows using T-SQL, we might write a query like this:

The logic is clear: Join rows from the two sets together on the primary key column, and return rows where a change has occurred in one or more data columns.
Unfortunately, this query only finds one of the expected four rows:

The problem is that our query does not correctly handle NULLs.
The ‘not equal to’ operators <> and != do not evaluate to TRUE if one or both of the expressions concerned is NULL.
In this example, that statement is always true because we are comparing column references. In other circumstances, the behaviour might depend on the ANSI_NULLS setting. I am not going to go into that here, partly because new code should be written to assume SET ANSI_NULLS ON:

One obvious way to handle the NULLs in our example is to write all the conditions out in full:

That query produces the correct results (only the row with PK = 4 is identical in both sets):
Even with just three columns to check, the query is already getting quite long. It is also quite easy to miss one of the combinations or to misplace a parenthesis.
In an attempt to reduce the size of the query, we might be tempted to use ISNULL or COALESCE:

The idea there is to replace any NULLs in the data with a particular non-null value that allows the comparison to work as we expect.
This produces the correct result (with the test data) but there are a number of reasons to dislike this approach.
For one thing, we have to be careful to choose a special replacement value that can never appear in the real data, now or at any time in the future. Taking this approach is no different, in principle, from choosing not to store NULLs in the first place, and using the chosen special value instead.
Leaving the ‘to null or not to null’ debate to one side, another issue is that COALESCE returns a value typed according to the input expression that has the highest data type precedence.
Many times, this will not matter, but it is possible to introduce subtle bugs this way. Using ISNULL instead would avoid this issue by ensuring that the data type of the first expression is used, but the problem of choosing appropriate special values remains.
The final objection I have to this method is a bit more subjective: although the query looks simpler than before, COALESCE is just shorthand for a CASE expression.
Let’s compare the execution plans for the two queries:

That’s the plan for the query with all the conditions written out in full. The Filter operator contains this mess:

The COALESCE form execution plan looks like this:

Now, the complexity is split between two operators. The Compute Scalar contains the definitions shown below on the left, and the Clustered Index Seek contains the residual predicate shown on the right:

Using ISNULL instead makes some difference — the graphical plan is visually identical to that obtained by using COALESCE, but the defined values and residual predicate are somewhat more concise:

An Alternative Syntax
We are looking for rows that join based on the value of the PK column, but which contain a difference in at least one column.
Another way to state that is to say:
For each row that joins, the intersection of the two rows should be empty.
If the two rows are identical the intersection of the two rows will be a single row. Conversely if the two rows are different in any way, the intersection will be empty.
Writing that logic in T-SQL results in this query form:

The query accounts for NULLs correctly, and produces the correct result. The query plan looks like this:

There are no surprises in the Clustered Index Scan, Clustered Index Seek, or Inner Join. In particular, none of these operators define any expressions or apply any residual predicates.
The seek is the one we would expect: It seeks to the row with the matching PK column value.
Looking at the Constant Scan reveals nothing, literally. This operator produces a single in-memory row with no columns. There really is nothing to see there, so we will move on to the last remaining operator: the Left Anti Semi Join.
If you were expecting to see complex logic similar to the CASE expressions seen earlier, prepare for a disappointment. The anti semi join contains the following:

Aside from a (redundant) check that the two PK columns match, this predicate just checks that all three data column values match, using an equality (=) comparison. (As a side note, we can avoid the redundant check on PK values by specifying just the data columns in the INTERSECT sub-query, rather than using the star * syntax).
To see how this works, consider that a left anti semi join passes rows through where no row is found on the inner input.
In this case, a row (with no columns) is always provided by the Constant Scan, but the predicate shown above is applied to it before the anti semi join decides whether to pass the source row on or not.
If all the conditions evaluate to TRUE, the no-column row from the Constant Scan is retained. The anti semi join finds that row on its inner input, and the source row does not pass on to the query output.
The net effect is that if the two rows match in all columns, no row appears on the output. In all other cases (where at least one difference exists) the current row is returned by the execution plan.
This is the correct semantic, so the query returns the correct result.
NULL handling trickery
At this point, you might be wondering how this query plan manages to handle NULLs correctly.
Consider the rows in the source tables with PK = 4. Both rows are identical, but only if the NULLs present in the ival column compare equal.
The relevant part of the predicate shown above is:

In the case where both columns contain NULL, we would expect this equality comparison to return UNKNOWN, not the TRUE needed to ensure that the anti semi join does not pass the source row to the output.
In other words, unless this equality comparison is doing something unusual, we would expect the query to incorrectly return a row for PK = 4 because the NULLs in the ival column should not compare equal.
The reason it works lies in the way INTERSECT handles NULLs. According to the documentation:

That explains why the INTERSECT query produces correct results, but it does not say how the query plan achieves this.
Before we see the details of that, let’s look at what happens if we try to write the query using the same logic as the INTERSECT plan:

That query produces the exact same graphical query plan as the INTERSECT query:

Even the predicate on the Anti Semi Join is identical:

Despite the identical plan, this new query produces wrong results! It includes the row with PK = 4 in the output, due to the problem comparing the NULLs in those rows:

The Answer
Although the graphical query plan (and even the extra detail available in the SSMS Properties window) shows no difference between the INTERSECT and NOT EXISTS queries, there is a difference — one that implements the different comparison semantics involved.
In the INTERSECT form, the equality comparison must compare two NULLs as equal. In the NOT EXISTS form, we are using a regular = comparison, one that should return UNKNOWN when two NULLs are compared.
To see this difference, we have to look deeper into the execution plan than the graphical form or Properties window can take us.
Inspecting the XML behind the graphical plan, we see the following logic in both cases for the test on the PK column values:
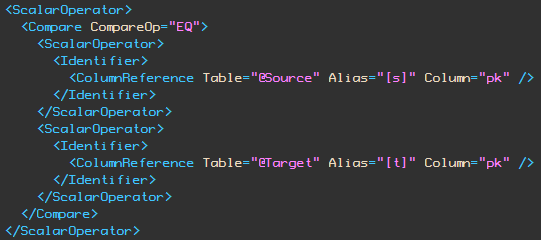
Notice the compare operation is EQ — a test for equality between the two column references. The EQ test does not return true for NULLs.
In the NOT EXISTS form of the query, the other columns are compared in exactly the same way, using EQ comparisons. For example, this is the test on the ival column:

Now look at the XML for the ival column comparison in the INTERSECT query:

Now the compare operation is shown as IS instead of EQ.
This is the reason that NULLs compare equal in the INTERSECT test. It is using the comparison semantic familiar to T-SQL users from expressions like WHERE x IS NULL.
This is the SQL language IS DISTINCT FROM feature —implemented in the query processor, but not yet available in the T-SQL language.
I would like to see the internal language of the query processor exposed as an alternative to T-SQL. The query processor’s query specification language is much richer and more expressive than T-SQL, and would not be bound by some of the odd behaviours maintained in T-SQL for backward compatibility. I live in hope, but I’m not holding my breath…
© Paul White
email: SQLkiwi@gmail.com
twitter: @SQL_Kiwi
Test script
USE Sandpit;
DECLARE @Set1 table
(
pk bigint PRIMARY KEY,
ival integer NULL,
cval char(1) NULL,
mval money NULL
);
DECLARE @Set2 TABLE
(
pk bigint PRIMARY KEY,
ival integer NULL,
cval char(1) NULL,
mval money NULL
);
INSERT @Set1
(pk, ival, cval, mval)
VALUES
(1, 1000, 'a', $1),
(2, NULL, 'b', $2),
(3, 3000, 'c', NULL),
(4, NULL, 'd', $4),
(5, 5000, 'e', $5);
INSERT @Set2
(pk, ival, cval, mval)
VALUES
(1, 1000, 'a', NULL),
(2, 2000, 'b', $2),
(3, NULL, 'c', $3),
(4, NULL, 'd', $4),
(5, 5999, 'z', $5);
-- Incorrect results, doesn't account for NULLs
SELECT
*
FROM @Set1 AS t
JOIN @Set2 AS s ON
s.pk = t.pk
WHERE
s.ival <> t.ival
OR s.cval <> t.cval
OR s.mval <> t.mval;
-- Correct, but verbose and error-prone
SELECT
*
FROM @Set1 AS t
JOIN @Set2 AS s ON
s.pk = t.pk
WHERE
s.ival <> t.ival
OR (s.ival IS NULL AND t.ival IS NOT NULL)
OR (s.ival IS NOT NULL AND t.ival IS NULL)
OR s.cval <> t.cval
OR (s.cval IS NULL AND t.cval IS NOT NULL)
OR (s.cval IS NOT NULL AND t.cval IS NULL)
OR s.mval <> t.mval
OR (s.mval IS NULL AND t.mval IS NOT NULL)
OR (s.mval IS NOT NULL AND t.mval IS NULL);
-- COALESCE: Correct results, but problematic
SELECT
*
FROM @Set1 AS t
JOIN @Set2 AS s ON
s.pk = t.pk
WHERE
COALESCE(s.ival, -2147483648) <> COALESCE(t.ival, -2147483648)
OR COALESCE(s.cval, '¥') <> COALESCE(t.cval, '¥')
OR COALESCE(s.mval, $-922337203685477.5808 ) <> COALESCE(t.mval, $-922337203685477.5808);
-- ISNULL: Correct results, but problematic
SELECT
*
FROM @Set1 AS t
JOIN @Set2 AS s ON
s.pk = t.pk
WHERE
ISNULL(s.ival, -2147483648) <> ISNULL(t.ival, -2147483648)
OR ISNULL(s.cval, '¥') <> ISNULL(t.cval, '¥')
OR ISNULL(s.mval, $-922337203685477.5808 ) <> ISNULL(t.mval, $-922337203685477.5808);
-- INTERSECT:
-- Correct results in a compact form
SELECT
*
FROM @Set1 AS t
JOIN @Set2 AS s ON
s.pk = t.pk
WHERE
NOT EXISTS (SELECT s.* INTERSECT SELECT t.*);
-- NOT EXISTS:
-- Same query plan, but wrong results!
SELECT
*
FROM @Set2 AS s
JOIN @Set1 AS t ON
t.pk = s.pk
WHERE
NOT EXISTS
(
SELECT 1
WHERE
t.pk = s.pk
AND t.ival = s.ival
AND t.cval = s.cval
AND t.mval = s.mval
);
Paul,
ReplyDeleteI ran across this accidentally almost, after years of using HASHBYTES with the XML clause as a poor man's row change identifier. The internet is littered with struggles in this area. I can't believe I JUST ran across it. I'm surprised this isn't linked to more often.
Considering this was the 2011 time frame, is there anything new(er) you've written on the subject or seen that you tend to lean more towards today?
Thanks for taking the time out to post this.
--J
No, there's nothing newer. The information in this posting is still accurate, and I use it every day.
DeleteThe post does get cited and linked to a lot (e.g. https://stackoverflow.com/a/19529391) and is gradually becoming "common knowledge" I think. Still, I will accept I don't do the best SEO :).
One day SQL Server might support `IS DISTINCT FROM`.
Looks like the OR NULL AND NULL syntax optimizes down these days also, tested on 2016
Delete'IS DISTINCT FROM' is now available in the 2022 perview, but, curiously, missing from any Azure SQL species. This is highly unusual since it's my understanding that the on-prem kernel is now considered the "cloud-scale tested" product of Azure functionality. Does anyone have an idea of the specifics about this unusual circumstance?
DeleteDwainew,
DeleteSome features and fixes (preview or otherwise) appear in the box product first, some (most) appear on cloud versions first. There has been a preference to release cloud first in the past, but it's not an absolute rule.
I remember using COALESCE / ISNULL in such cases, whilte this trick is briefer in syntax and has better performance. Neat little gem to be added to one's knowledgebase.
ReplyDeleteThanks. Yes, and as I say in the article, using either of those requires choosing a special replacement value that can *never* appear in the real data, now or at any time *in the future*. That can be tricky to guarantee.
DeleteHi,
ReplyDeleteFor this problem, I use the EXCEPT clause. Is there anything fundamentally wrong with it? Seems the simplest solution to me, but I might be wrong:
SELECT * FROM @Set1 AS t EXCEPT SELECT * FROM @Set2 AS s
If you want the exact same results as in your query (i.e. columns from both tables), you could write a CTE:
WITH DIFF as (SELECT * FROM @Set1 AS t EXCEPT SELECT * FROM @Set2 AS s) --- DIFFERENT ROWS
SELECT t.*,s.* FROM @Set1 AS t JOIN @Set2 AS s ON s.pk = t.pk --- JUST THE COLUMNS YOU WANTED
JOIN DIFF on DIFF.pk = t.pk --- ONLY KEEP THE DIFFERENT ROWS
The execution plan to have the identical results seems longer (3 nested loops), but as there are very few rows, it is not really indicative of how it scales with larger datasets. The plan does the left-anti-join loop first.
Would you prefer one solution or the other?
Thanks
zenzei,
DeleteNo there's nothing wrong with EXCEPT — it's the same idea.
The CTE code you gave that produces the desired results seems a lot less efficient and harder to read than the original:
SELECT *
FROM @Set1 AS t
JOIN @Set2 AS s ON s.pk = t.pk
WHERE NOT EXISTS (SELECT s.* INTERSECT SELECT t.*);
You could write the WHERE clause as "EXISTS (SELECT s.* EXCEPT SELECT t.*);"
I usually find INTERSECT gives a slightly cleaner execution plan.
Hi Paul,
ReplyDeleteI was mainly comparing the short versions:
SELECT * FROM @Set1 AS t EXCEPT SELECT * FROM @Set2 AS s --seems quite clean and short...
versus
SELECT t.* --only keeping columns from Set1
FROM @Set1 AS t
JOIN @Set2 AS s ON s.pk = t.pk
WHERE NOT EXISTS (SELECT s.* INTERSECT SELECT t.*);
When comparing these two, in the short examples you provided, the except version seemed to be shorter to write and with a simpler plan.
But of course, life is all about trying with real volumes, so I tested the above scenario (keeping only columns from Set1) with larger tables.
Three queries to compare:
1 - Your query with WHERE...NOT EXISTS... INTERSECT...
2 - Same query with WHERE...EXISTS...EXCEPT
3 - Simple query only with EXCEPT
I then created two #set1, #set2 tables with 13M rows, with the following characteristics:
Test 1: HEAP tables
Test 2: clustered columnstore indexed
Results:
- Queries 1 and 2 run much faster than Query 3 (the simple except) - couple of seconds vs 9 seconds (test1) or 20 seconds (test2). Huge difference.
- Query 1 is still faster than Query 2 (1 second vs 2 seconds). Queries 1 and 2 generate different plan. Query2 has one more nested loop
- Clustered columnstore makes Query3 much slower (needs a sort), while it still is fast on Query 1 and 2.
So, as I was secreatly really expecting, your plan is better and much faster.
Now, there is only one caveat: Queries 1 and 2 rely on having an *unique* PK (or a combination of columns that act as such that you can put in the join).
If there is a duplicate or nulls in the joining column(s), Queries 1 and 2 will report both rows as being different, while Query3 (the one using only Except) will correctly only report the differences.
So Query 3 is more generic for these cases, but if you have PK the best version by far is the one you provided.
Hope this is useful, thanks for all your blogging and writing, I learnt a lot from them.
It seems that the IS operator is only exhibited in the plan if the comparison is between two columns, not between a column and a variable. I get seemingly identical plans for the three variations below. The result is nevertheless not the same for the first one as the latter two:
ReplyDeleteDROP TABLE IF EXISTS DemoTable
CREATE TABLE DemoTable(a int NOT NULL,
b int NOT NULL,
c int NULL,
d int NULL,
CONSTRAINT pk_DemoTable PRIMARY KEY (a, b),
INDEX c_d_ix NONCLUSTERED (c, d)
)
go
INSERT DemoTable (a, b, c, d)
SELECT object_id, column_id, iif(max_length = -1, NULL, abs(checksum(*) % 200)),
IIf(len(name) = 8, NULL, abs(checksum(*) % 100))
FROM sys.columns
go
CREATE OR ALTER PROCEDURE GetDataByCD @c int, @d int AS
SELECT a, b, c, d
FROM DemoTable
WHERE c = @c
AND d = @d
go
EXEC GetDataByCD NULL, NULL
go
CREATE OR ALTER PROCEDURE GetDataByCD @c int, @d int AS
SELECT a, b, c, d
FROM DemoTable
WHERE (c = @c OR c IS NULL AND @c IS NULL)
AND (d = @d OR d IS NULL AND @d IS NULL)
go
EXEC GetDataByCD NULL, NULL
go
CREATE OR ALTER PROCEDURE GetDataByCD @c int, @d int AS
SELECT a, b, c, d
FROM DemoTable
WHERE EXISTS (SELECT c, d INTERSECT SELECT @c, @d)
go
EXEC GetDataByCD NULL, NULL
Hi Erland,
ReplyDeleteIt's not so much what the comparison is between (column, variable, parameter...), rather it is the accuracy of the showplan representation of the internal plan.
The comparison is always correctly IS or EQ depending on the requested semantic.
In your case, it is the way the seek predicate comparison is rendered. Remove the nonclustered index to see EQ or IS in showplan. Alternatively, add OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607) to the statement in the procedure to see ScaOp_Comp x_cmpIs or x_cmpEq in the optimizer output.
Cheers,
Paul