As usual, here’s a sample table:
CREATE TABLE #Example
(
pk numeric IDENTITY PRIMARY KEY NONCLUSTERED,
col1 sql_variant NULL,
col2 sql_variant NULL,
thing sql_variant NOT NULL,
);
Some sample data:

And an index that will be useful shortly:
CREATE INDEX nc1
ON #Example
(col1, col2, thing);
There’s a complete script to create the table and add the data at the end of this post. There’s nothing special about the table or the data (except that I wanted to have some fun with values and data types).
The Task
We are asked to return distinct combinations of col1 and col2, plus any one value from the thing column (it doesn’t matter which) per col1, col2 group.
One possible result set is shown below:

There are many ways to write a query to do this in SQL. In fact, there are a surprising number of alternatives, a point I might return to in a future post.
Using the MAX aggregate
For now, let’s take a look at one natural SQL query solution:
SELECT
e.col1,
e.col2,
MAX(e.thing)
FROM #Example AS e
GROUP BY
e.col1,
e.col2;
The execution plan is:

There’s absolutely nothing wrong with this query or execution plan. The query is concise, returns the correct results, and executes quickly.
So why am I blogging about it? It’s the aggregate function. It bothers me that I have to use MAX (or MIN) here, when what I really want to write is something like:
SELECT
e.col1,
e.col2,
ANY (e.thing)
FROM #Example AS e
GROUP BY
e.col1,
e.col2;
The ANY aggregate
Sadly, that’s not valid syntax; there’s no ANY aggregate in T-SQL. But, just because we can’t use an ANY aggregate doesn’t mean the SQL Server query processor can’t…
There’s an alternative way to think about the query we want to write: If we were to partition the input set on the grouping columns, and (arbitrarily) number the rows within each partition, we could just choose row #1 from each partition.
In T-SQL, we can use the ROW_NUMBER window function to do this:
SELECT
e.col1,
e.col2,
e.thing
FROM
(
SELECT
*,
rn = ROW_NUMBER() OVER (
PARTITION BY e2.col1, e2.col2
ORDER BY e2.col1, e2.col2)
FROM #Example AS e2
) AS e
WHERE
e.rn = 1;
If you are familiar with execution plans, you might expect that query to produce one that looks something like this:

In the above imaginary plan:
- The Index Scan produces rows ordered by
col1andcol2 - The Segment detects the start of each new group and sets a flag in the stream
- The Sequence Project uses that flag to restart row numbering for each group
- The Filter restricts the output to rows where the row number is 1.
In fact, we don’t get a plan like that at all, we get this:

This is the same plan produced for the query with the MAX aggregate!
Well, actually it isn’t quite the same. If you click on the Stream Aggregate and take a look at its properties, you’ll see it isn’t performing a MAX aggregate.
These are the values defined by the aggregate in the new query:
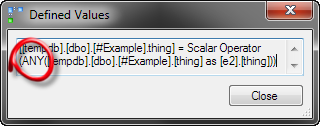
For comparison, these are the values defined by the MAX query:

Our new query form is using the ANY aggregate!
What Magic Is This?
SQL Server spotted that we didn’t really want to number the rows at all. We were just expressing the idea that we want one row per group and we don’t care which one.
The simplification rule used to perform this is called SelSeqPrjToAnyAgg. As the name suggests, it matches on a Selection (Filter) and a Sequence Project (specifically one that uses ROW_NUMBER) and replaces it with the ANY aggregate.
It is a simplification rule, so it runs before full cost-based optimization, making this transformation available even in trivial plans.
This particular optimization only matches very specific plan shapes, so you have to be careful with it:
- The Filter has to restrict the expression produced by the Sequence Project to be equal to one. In our query, that correlates to the
WHERE rn = 1expression. - The expression added by the Sequence Project must not form part of the query result.
- You have to
PARTITION BYandORDER BYthe grouping columns (though the order does not matter). - The non-grouping columns must be constrained
NOT NULL.
Specifying a constant for the ORDER BY clause of the window function (to indicate that you don’t care about ordering) does not work:

That query (and ones like it that use (ORDER BY … (SELECT 0), NULL, or NEWID() etc.) fail to match the rule, resulting in the Segment, Sequence Project, and Filter plan. (If you use SELECT <constant> you will see an extra Compute Scalar):

If you want to take advantage of the ANY aggregate rewrite, you have to be careful to match the conditions for the rewrite exactly.
The Invisible ANY
Let’s drop the index we created earlier:
DROP INDEX nc1 ON #Example;
Now if we run the rule-matching ROW_NUMBER form of the query, we get this plan instead:

As I mentioned in my previous post on Row Goals and Grouping, a Sort followed by a Stream Aggregate can be transformed to a Sort running in Distinct Sort mode.
The Stream Aggregate (with its ANY aggregate) is subsumed by the Sort, and in the process, the ANY aggregation is lost to us.
It is logically still there, but not exposed in the query plan, not even in the XML:

The Sort produces the three columns needed (col1, col2, and thing), and performs a Distinct ordered by col1 and col2, but there’s no longer any explicit reference to the ANY aggregate performed on the thing column.
To make it reappear, we need to temporarily disable the optimizer rule responsible for the transformation to Distinct Sort:

Now we see a plan with the separate Sort and a Stream Aggregate containing the ANY aggregate:

ANY Hash Aggregate
The final thing I want to show today is the ANY aggregate working in a Hash Match Aggregate.
If we use an OPTION (HASH GROUP) query hint, we get this plan:

As promised, you can find the script for today’s entry below. For more information on optimizer rules and internals, see my previous mini-series:
Inside the Optimizer: Constructing a Plan
© Paul White
email: SQLkiwi@gmail.com
twitter: @SQL_Kiwi
Script
USE Sandpit;
DBCC FREEPROCCACHE;
IF OBJECT_ID(N'tempdb.bdpmet.#Example', N'U') IS NOT NULL
BEGIN
DROP TABLE tempdb.penguin.#Example;
END;
GO
CREATE TABLE #Example
(
pk numeric IDENTITY PRIMARY KEY NONCLUSTERED,
col1 sql_variant NULL,
col2 sql_variant NULL,
thing sql_variant NOT NULL,
);
GO
INSERT #Example
(col1, col2, thing)
VALUES
('A1', CONVERT(sql_variant, $100), CONVERT(sql_variant, PI())),
('A1', $100, {guid '1D008813-8E80-4821-A481-1A0DE5C4F4DC'}),
('A1', $100, 7.297352569824),
('A1', N'-U-', 1.3E8),
('A1', N'-U-', 9.10938291),
('A1', N'-U-', @@SERVICENAME),
('A2', {d '2011-07-11'}, 'aotearoa'),
('A2', {d '2011-07-11'}, 0xDEADBEEF),
('A2', {d '2011-07-11'}, N'संहिता'),
('A3', 1.054571726, {fn CURRENT_TIME}),
('A3', 1.054571726, RADIANS(RAND())),
('A3', 1.054571726, {fn DAYNAME (0)});
GO
CREATE INDEX nc1
ON #Example
(col1, col2, thing);
GO
-- A natural query:
SELECT
e.col1,
e.col2,
MAX(e.thing)
FROM #Example AS e
GROUP BY
e.col1,
e.col2;
GO
-- Would prefer:
SELECT
e.col1,
e.col2,
ANY (e.thing)
FROM #Example AS e
GROUP BY
e.col1,
e.col2;
GO
-- Transformed to use ANY
SELECT
e.col1,
e.col2,
e.thing
FROM
(
SELECT
*,
rn = ROW_NUMBER() OVER (
PARTITION BY e2.col1, e2.col2
ORDER BY e2.col1, e2.col2)
FROM #Example AS e2
) AS e
WHERE
e.rn = 1;
GO
-- Not matched, no ANY aggregate
SELECT
e.col1,
e.col2,
e.thing
FROM
(
SELECT
*,
rn = ROW_NUMBER() OVER (
PARTITION BY e2.col1, e2.col2
ORDER BY (SELECT 0))
FROM #Example AS e2
) AS e
WHERE
e.rn = 1;
GO
-- Not matched - we use the rn column
SELECT
e.col1,
e.col2,
e.thing,
e.rn
FROM
(
SELECT
*,
rn = ROW_NUMBER() OVER (
PARTITION BY e2.col1, e2.col2
ORDER BY e2.col1, e2.col2)
FROM #Example AS e2
) AS e
WHERE
e.rn = 1;
GO
DROP INDEX nc1 ON #Example;
GO
-- Distinct Sort with invisible ANY
SELECT
e.col1,
e.col2,
e.thing
FROM
(
SELECT
*,
rn = ROW_NUMBER() OVER (
PARTITION BY e2.col1, e2.col2
ORDER BY e2.col1, e2.col2)
FROM #Example AS e2
) AS e
WHERE
e.rn = 1;
GO
-- Disable rule
DBCC RULEOFF('GbAggToSort');
-- Same query, recompile to force re-optimization
SELECT
e.col1,
e.col2,
e.thing
FROM
(
SELECT
*,
rn = ROW_NUMBER() OVER (
PARTITION BY e2.col1, e2.col2
ORDER BY e2.col1, e2.col2)
FROM #Example AS e2
) AS e
WHERE
e.rn = 1
OPTION (RECOMPILE);
-- Enable rule again (*** IMPORTANT! ***)
DBCC RULEON('GbAggToSort');
GO
-- ANY aggregate with Hash Match
SELECT
e.col1,
e.col2,
e.thing
FROM
(
SELECT
*,
rn = ROW_NUMBER() OVER (
PARTITION BY e2.col1, e2.col2
ORDER BY e2.col1, e2.col2)
FROM #Example AS e2
) AS e
WHERE
e.rn = 1
OPTION (HASH GROUP);
No comments:
Post a Comment
All comments are reviewed before publication.