Introduction
You probably already know that it’s important to be aware of data types when writing queries, and that implicit conversions between types can lead to poor query performance.
Some people have gone so far as to write scripts to search the plan cache for CONVERT_IMPLICIT elements, and others routinely inspect plans for that type of thing when tuning.
Now, that’s all good, as far as it goes. It may surprise you to learn that not all implicit conversions are visible in query plans, and there are other important factors to consider too.
To demonstrate, I’m going to use two single-column heap tables, containing a selection of pseudo-random numbers, as shown in the diagram below (there’s a script to create the test tables and data at the end of this post):
The first table contains 5,000 rows, and the second table contains 5,000,000 rows.
The basic test query is to count the number of rows returned by an inner join of the two tables. We’ll run a number of tests to explore the performance issues, using tables with different data types to store the data.
Test One – integer NOT NULL
The first test features two tables where both columns are typed as integer, and constrained to be NOT NULL:

Since one table is significantly smaller than the other, the query optimizer chooses a hash join.
To avoid the (very useful) bitmap filter optimization featured in my last post, each query features a MAXDOP 1 query hint to guarantee a serial plan.
The test query gives this query plan:

This returns its result in 900ms.
Test Two – integer to real
Now let’s try the same query, but where the larger table’s column uses the real data type. The smaller table is integer as before:

The execution plan is:

There are a couple of new things here.
First, SQL Server needs to convert the data type of one of the columns to match the other before it can perform the join.
The rules of data type precedence show that real has a higher precedence than integer, so the integer data is converted to real using the CONVERT_IMPLICIT operation shown in the Compute Scalar iterator.
The join then probes the hash table (built on the converted real values) for matches.
The possibility of hash collisions means that a residual predicate is applied to check that the values indicated as a possible match actually do match. Nothing much new or surprising here.
The query performs slightly less well than before, completing in 1000ms.
Test Three – integer to decimal
Same query again, but this time the larger table’s column is defined as a decimal(7, 0):

The execution plan is:

The first surprise is that this query takes 1600ms.
The second surprise is that the query plan does not contain a Compute Scalar or a CONVERT_IMPLICIT anywhere, despite the fact that we are joining columns with different data types.
In fact there is no indication anywhere that an implicit conversion is occurring — not in the graphical plan, not even in the more detailed XML show plan representation.
This is very bad news. Whether you are tuning the query by hand, or using a script to scan the plan cache for implicit conversions, there really is no way to see the invisible type conversion here. Even the implicit type conversion warnings introduced with SQL Server 2012 do not detect the problem.
Test Four – decimal to integer
Now let’s reverse the situation, so the smaller table’s column is decimal(7,0) and the larger table is integer:

The execution plan is:

Now the query runs for 1900ms.
The data precedence rules mean each integer value from the large table has to be converted to decimal to compute a hash value, and converted again to check the residual.
Again, there is no Compute Scalar, no CONVERT_IMPLICIT…absolutely no visible indication anywhere why this query should run over twice as long as the original.
Adding an Explicit Conversion
Let’s see what happens if we introduce an explicit conversion, choosing to convert the decimal values to integer in order to perform the conversion on the smaller table:

The execution plan is:

Ok, so now we have a Compute Scalar, an explicit CONVERT, and a Probe Residual that references the converted expression.
This query completes in 1000ms.
Compare this query plan with the one shown immediately above it. Would you pick that the plan with the extra Compute Scalar would be nearly twice as fast?
Conversion Families
So what’s going on here? Why is SQL Server hiding conversion details from us that have such a profound effect on execution speed?
It turns out that certain implicit conversions can be performed inside the join, and so do not require a separate Compute Scalar. This is the case if the join columns have different types, but both types come from the same ‘family’.
The five families are:
| family | types |
|---|---|
| 1 | bigint, integer, smallint, tinyintbit, decimal, smallmoney, money |
| 2 | datetime, datetime2date, datetimeoffset |
| 3 | char, varchar |
| 4 | nchar, nvarchar |
| 5 | binary, varbinary |
In our example, decimal and integer are from family #1 so the implicit conversion can be performed inside the join, without a CONVERT_IMPLICIT or Compute Scalar.
Stop for a moment and think about how many joins you have in production code where the columns involved are integer to bigint, or smallint to integer, to take just a couple of possible examples.
Are those joins running at half speed?
The NULL Issue
There is one more subtlety to consider. Let’s run our test query one last time, using tables with integer columns, but this time the columns are declared as allowing NULLs (there are no NULLs in the test data, by the way).

Execution plan:
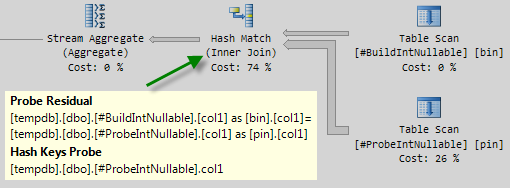
This query runs in around 1000ms.
Remember the first query we ran (where both columns were defined as integer NOT NULL) completed in 900ms.
Let’s look at that first query plan again:
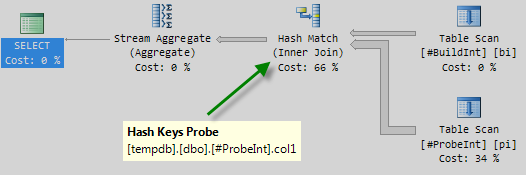
Notice the lack of a Probe Residual.
If the join is on a single column typed as tinyint, smallint, or integer and if both columns are constrained to be NOT NULL, the hash function is ‘perfect’ — meaning there is no chance of a hash collision, and the query processor does not have to check the values again to ensure they really match.
This optimization is the reason that the NOT NULL query performs 11% faster than when either or both join columns allow NULLs.
Note that this optimization does not apply to bigint columns.
The general rule is that the data type needs to fit in 32 bits.
Perfect hashing can also be achieved with tinyint NULL and smallint NULL data types, because even with an extra bit for the null, the range of possible values fits within 32 bits.
To achieve a join without Probe Residiual with these nullable types, the join condition must not reject nulls. As described in Equality Comparisons, a convenient way to achieve that uses INTERSECT:
CREATE TABLE #BuildTinyIntNull (c1 tinyint NULL);
CREATE TABLE #ProbeTinyIntNull (c1 tinyint NULL);
-- Long form
SELECT COUNT_BIG(*)
FROM #BuildTinyIntNull AS B
JOIN #ProbeTinyIntNull AS P
ON (P.c1 = B.c1)
OR (P.c1 IS NULL AND B.c1 IS NULL);
-- Equivalent
SELECT COUNT_BIG(*)
FROM #BuildTinyIntNull AS B
JOIN #ProbeTinyIntNull AS P
ON EXISTS (SELECT P.c1 INTERSECT SELECT B.c1);
Summary
General advice for best join performance:
- Be aware that conversions may occur without a
CONVERT_IMPLCITor Compute Scalar - Join on a single column
- Ensure join column types match exactly
- Constrain potential join columns to be
NOT NULL - Use
tinyint,smallint, orintegertypes to avoid residual predicates - Introduce explicit conversions where necessary, as a workaround
I will cover further reasons to prefer integer NOT NULL in a future post.
Further Reading
Hash Match Probe Residual by Rob Farley
Test Script:
USE tempdb;
GO
DROP TABLE
#BuildInt, #BuildIntNullable, #BuildBigInt, #BuildDec, #BuildReal,
#ProbeInt, #ProbeIntNullable, #ProbeBigInt, #ProbeDec, #ProbeReal;
GO
-- Test tables
CREATE TABLE #BuildInt
(
col1 INTEGER NOT NULL
);
GO
CREATE TABLE #BuildIntNullable
(
col1 INTEGER NULL
);
GO
CREATE TABLE #BuildBigInt
(
col1 BIGINT NOT NULL
);
GO
CREATE TABLE #BuildDec
(
col1 DECIMAL(7,0) NOT NULL
);
GO
CREATE TABLE #BuildReal
(
col1 REAL NOT NULL
);
GO
CREATE TABLE #ProbeInt
(
col1 INTEGER NOT NULL
);
GO
CREATE TABLE #ProbeIntNullable
(
col1 INTEGER NULL
);
GO
CREATE TABLE #ProbeBigInt
(
col1 BIGINT NOT NULL
);
GO
CREATE TABLE #ProbeDec
(
col1 DECIMAL(7,0) NOT NULL
);
GO
CREATE TABLE #ProbeReal
(
col1 REAL NOT NULL
);
GO
------------------------------------------------
-- Load 5,000 INTEGER rows into the build tables
------------------------------------------------
SET NOCOUNT ON;
SET STATISTICS IO, TIME, XML OFF;
DECLARE @I INTEGER = 1;
INSERT #BuildInt
(col1)
VALUES
(CONVERT(INTEGER, RAND(1) * 9999999));
WHILE @I < 5000
BEGIN
INSERT #BuildInt
(col1)
VALUES
(RAND() * 9999999);
SET @I += 1;
END;
-- Copy to the INT nullable build table
INSERT #BuildIntNullable
(col1)
SELECT
bi.col1
FROM #BuildInt AS bi;
-- Copy to the BIGINT build table
INSERT #BuildBigInt
(col1)
SELECT
CONVERT(BIGINT, bi.col1)
FROM #BuildInt AS bi;
-- Copy to the DECIMAL build table
INSERT #BuildDec
(col1)
SELECT
CONVERT(DECIMAL(7,0), bi.col1)
FROM #BuildInt AS bi;
-- Copy to the REAL build table
INSERT #BuildReal
(col1)
SELECT
CONVERT(REAL, bi.col1)
FROM #BuildInt AS bi;
----------------------------------------------------
-- Load 5,000,000 INTEGER rows into the probe tables
----------------------------------------------------
SET NOCOUNT ON;
SET STATISTICS IO, TIME, XML OFF;
DECLARE @I INTEGER = 1;
INSERT #ProbeInt
(col1)
VALUES
(CONVERT(INTEGER, RAND(2) * 9999999));
BEGIN TRANSACTION;
WHILE @I < 5000000
BEGIN
INSERT #ProbeInt
(col1)
VALUES
(CONVERT(INTEGER, RAND() * 9999999));
SET @I += 1;
IF @I % 100 = 0
BEGIN
COMMIT TRANSACTION;
BEGIN TRANSACTION;
END;
END;
COMMIT TRANSACTION;
-- Copy to the INT nullable probe table
INSERT #ProbeIntNullable
(col1)
SELECT
pri.col1
FROM #ProbeInt AS pri
-- Copy to the BIGINT probe table
INSERT #ProbeBigInt
(col1)
SELECT
CONVERT(BIGINT, pri.col1)
FROM #ProbeInt AS pri
-- Copy to the DECIMAL probe table
INSERT #ProbeDec
(col1)
SELECT
CONVERT(DECIMAL(7,0), pri.col1)
FROM #ProbeInt AS pri
-- Copy to the REAL probe table
INSERT #ProbeReal
(col1)
SELECT
CONVERT(DECIMAL(7,0), pri.col1)
FROM #ProbeInt AS pri
-----------
-- TESTS --
-----------
SET STATISTICS IO, TIME ON;
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #ProbeInt AS pri ON
pri.col1 = bi.col1
OPTION (MAXDOP 1);
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #ProbeIntNullable AS pin ON
pin.col1 = bi.col1
OPTION (MAXDOP 1);
SELECT
COUNT_BIG(*)
FROM #BuildIntNullable AS bin
JOIN #ProbeIntNullable AS pin ON
pin.col1 = bin.col1
OPTION (MAXDOP 1);
SELECT
COUNT_BIG(*)
FROM #BuildIntNullable AS bin
JOIN #ProbeInt AS pri ON
pri.col1 = bin.col1
OPTION (MAXDOP 1);
SELECT
COUNT_BIG(*)
FROM #BuildBigInt AS bbi
JOIN #ProbeBigInt AS pbi ON
pbi.col1 = bbi.col1
OPTION (MAXDOP 1);
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #ProbeDec AS pd ON
pd.col1 = bi.col1
OPTION (MAXDOP 1);
SELECT
COUNT_BIG(*)
FROM #BuildDec AS bd
JOIN #ProbeInt AS pri ON
pri.col1 = bd.col1
OPTION (MAXDOP 1);
SELECT
COUNT_BIG(*)
FROM #BuildDec AS bd
JOIN #ProbeInt AS pri ON
pri.col1 = CONVERT(INTEGER, bd.col1)
OPTION (MAXDOP 1);
SELECT
COUNT_BIG(*)
FROM #BuildDec AS bd
JOIN #ProbeInt AS pri ON
CONVERT(DECIMAL(7,0), pri.col1) = bd.col1
OPTION (MAXDOP 1);
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #ProbeDec AS pd ON
pd.col1 = bi.col1
OPTION (MAXDOP 1);
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #ProbeReal AS pr ON
pr.col1 = bi.col1
OPTION (MAXDOP 1);
SELECT
COUNT_BIG(*)
FROM #BuildReal AS br
JOIN #ProbeInt AS pri ON
pri.col1 = br.col1
OPTION (MAXDOP 1);
SET STATISTICS IO, TIME OFF;
© Paul White
email: SQLkiwi@gmail.com
twitter: @SQL_Kiwi
No comments:
Post a Comment
All comments are reviewed before publication.