In my last post, Enforcing Uniqueness for Performance, I showed how using a unique index could speed up equality seeks by around 40%.
Today, I’m going to use the same tables as last time (single bigint column, one table with a non-unique clustered index, and one table with a unique clustered index):
CREATE TABLE dbo.SeekTest
(
col1 bigint NOT NULL,
);
GO
-- Non-unique clustered index
CREATE CLUSTERED INDEX cx
ON dbo.SeekTest (col1);
GO
CREATE TABLE dbo.SeekTestUnique
(
col1 bigint NOT NULL
);
GO
-- Unique clustered index
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.SeekTestUnique (col1);
Test Data
This time, instead of filling the tables with all the numbers from 1 to 5 million, we’ll add just the even numbers from 1 to 10 million.
At the risk of stating the obvious, this results in tables with the same number of rows as previously, just no odd numbers:
INSERT dbo.SeekTest WITH (TABLOCKX)
(col1)
SELECT TOP (5000000)
col1 =
2 * ROW_NUMBER() OVER (
ORDER BY @@SPID)
FROM
master.sys.columns AS C
CROSS JOIN master.sys.columns AS C2
CROSS JOIN master.sys.columns AS C3
ORDER BY
col1;
GO
INSERT dbo.SeekTestUnique WITH (TABLOCKX)
(col1)
SELECT TOP (5000000)
col1 =
2 * ROW_NUMBER() OVER (
ORDER BY @@SPID)
FROM
master.sys.columns AS C
CROSS JOIN master.sys.columns AS C2
CROSS JOIN master.sys.columns AS C3
ORDER BY
col1;
Non-Unique Index
The test is the same as before: Join the test table to itself using a nested loops join, and count the rows returned.
Don’t be fooled by the simplistic nature of the test; I realize you rarely use loops join to self join all the rows in a table.
The point here is to check how long it takes to perform 5 million row joins — something that probably happens quite often in most production systems, either as 5 million lookups into a single very much larger table, or perhaps by running a query that does 50,000 row-joins 100 times.
Here’s the query:
SELECT
COUNT_BIG(*)
FROM dbo.SeekTest AS ST
WITH (TABLOCK)
JOIN dbo.SeekTest AS ST2
WITH (TABLOCK)
ON ST2.col1 = ST.col1
OPTION (MAXDOP 1, LOOP JOIN, FORCE ORDER);
And the ‘actual’ query plan:

I get these performance results:
Table 'SeekTest'.
Scan count 5,000,001,
logical reads 15,969,038, physical reads 0, read-ahead reads 0
CPU time = 9251 ms, elapsed time = 9278 ms.
Notice the 5,000,001 scan count showing that we are performing 5 million range scans (not singleton seeks). Running this query with all the data in memory uses 9,251ms of CPU time.
Unique Index
We know from last time that we can improve on this result by making the index unique, and performing singleton seeks instead of range scans.
Let’s do that:
SELECT
COUNT_BIG(*)
FROM dbo.SeekTestUnique AS STU
WITH (TABLOCK)
JOIN dbo.SeekTestUnique AS STU2
WITH (TABLOCK)
ON STU2.col1 = STU.col1
OPTION (MAXDOP 1, LOOP JOIN, FORCE ORDER);
The actual execution plan is:
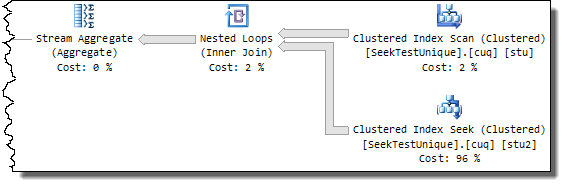
The performance results are:
Table 'SeekTestUnique'.
Scan count 1,
logical reads 15,323,030, physical reads 0, read-ahead reads 0
CPU time = 16,005 ms, elapsed time = 16,034 ms.
As expected, the scan count confirms we are now doing singleton seeks, and the CPU time has improved to 16,005ms.
Er, Hang On…
If you think that going from 9,251ms of CPU to 16,005ms of CPU is not exactly an improvement, you’d be right.
There’s no typo there, no inadvertent switching of the unique and non-unique examples, and no tricks.
Making the index unique really has slowed down this query by around 70%.
The explanation is so interesting, it deserves a full post of its own, so I will cover that in my next post.
Important
In general, you will want to specify an index as UNIQUE wherever you can. Many queries will benefit from a unique index rather than a non-unique one.
This post is very much to show “It Always Depends” and to set the stage for the next post in this series.
© Paul White
email: SQLkiwi@gmail.com
twitter: @SQL_Kiwi
No comments:
Post a Comment
All comments are reviewed before publication.