The following table summarizes the results from my last two articles, Enforcing Uniqueness for Performance and Avoiding Uniqueness for Performance. It shows the CPU time used when performing 5 million clustered index seeks into a unique or non-unique index:

In test 1, making the clustered index unique improved performance by around 40%.
In test 2, making the same change reduced performance by around 70% (on 64-bit systems – more on that later).
As a further reminder, both tests used nested loops to join a single-column table of bigint numbers to itself:

In test 1, the table contains numbers from 1 to 5 million inclusive. For test 2, the table contains the even numbers from 2 to 10 million (still 5 million rows).
In case you were wondering, the test 2 results are the same if we populate the table with odd numbers from 1 to 9,999,999 instead of even numbers.
How can we explain these results?
Performing an Index Seek
We need to look a bit deeper into how SQL Server performs an index seek.
Most people know that SQL Server indexes are a B+ tree. Let’s work through an example of locating the row containing the value 1 million, when the table contains values from 1 to 5 million, using a unique clustered index.
Index seeks start at the index root page, which we can find in a number of ways (e.g. sys.system_internals_allocation_units).
I happened to use DBCC IND to determine that the root of the index was page 117482 in file 1.
- Note
- In SQL Server 2012 and later, we can use a new, undocumented view:
sys.dm_db_database_page_allocations).
Whichever way you find the root page, we can use DBCC PAGE to look at the contents:

The col1 (key) column shows the lowest key value that can possibly be present in the lower-level page specified by ChildPageId.
We can see that the lowest possible key value on page 117485 is 906305, and the next lowest key value possible is 1132881 on page 117486. So, if a row containing the value 1 million exists, the next page to look at is 117485:

We are now at level 1 of the index, and have to scroll down the output a bit further to see that the next page to look at is 119580.
This page is at the leaf level of the index, and we find our target value at position 399:

Binary Search
When performing an index seek, SQL Server obviously doesn’t run DBCC PAGE and scroll down the output window visually to find the next page to look at like we just did.
You may already know that SQL Server can use a binary search to locate index entries, but it’s worth taking a closer look at the index pages to see how that works in practice:

The slot array contains a series of two-byte offsets pointing to the index records.
The index records are not necessarily stored in any particular order on the page. Only the slot array entries are guaranteed to be in sorted order.
Note that the sorted slot array entries do not contain the index keys themselves, just offsets.
Performance
When SQL Server uses binary search to locate an index entry, it starts by checking the middle element of the slot array (shown in red 02 in the example above).
It then follows that offset pointer to the index record, and compares the value it finds there with the sought value.
Assuming the value is not the one we are looking for, the sorted nature of the slot array allows SQL Server to narrow the search range in half after this first comparison.
If the red index record happens to contain a value higher than the sought value, we know the value we are looking for is in that half of the slot array that sorts lower than the red entry.
This process of cutting the search space in half continues until we find the record we are looking for, or until it becomes clear that the value does not exist.
The average and worst case performance of binary search is very close to log2N comparisons to find the item of interest in a sorted list of N items.
For the 476 index entries found in our test example index structure at the leaf level, that means at most 9 comparison operations. That compares well to a linear search of the sorted slot array, which might require as many as 476 comparisons if we are unlucky, 238 on average.
None of this offers any particular insight into why a binary search into a unique index containing only even (or odd!) numbers should be so slow.
One of the advantages of binary search is that it expects to perform around the same amount of work, regardless of the distribution of the values in the index.
Luckily, binary search is not the only game in town.
Linear Interpolation
As efficient as binary search is in the general case, in some cases we can do better.
When searching for the value 1 million, we know from level 1 of the index that the lowest key value that can appear on the leaf level page we are interested in is 999,601. We also know that the lowest key value on the next page is 1,000,077.
From the header information on our target page, we also know there are 476 entries in the slot array on that page. Given these facts, we can make an immediate guess at which slot the value 1,000,000 ought to appear in:
expected slot
= (1000077 - 999601) / 476 * (1000000 - 999601)
= 399
This calculation takes us immediately to slot 399. As we saw earlier, slot 399 does indeed contain the value 1,000,000:

The quality of the linear interpolation guess depends on how evenly distributed the values are within the page.
To a lesser extent, it also depends on how closely the minimum key value information at level 1 of the index matches reality.
In both tests shown in earlier blog entries, the values are precisely evenly distributed and the level 1 index key information is spot on.
Performance
Linear interpolation has the potential to be even more efficient than binary search, finding the target value in one comparison in this example, compared to nine comparisons for binary search.
Even where the data is not perfectly distributed, there is scope for linear interpolation to be superior, simply by applying the technique repeatedly on successively narrower ranges.
A reasonable practical compromise might be to try linear interpolation two or three times, before falling back to linear or binary search on the remaining range.
The advantage of linear interpolation may not seem much, but consider that SQL Server makes these comparisons for every index seek operation. When doing many millions of seeks, the difference can soon add up.
It is probably not coincidence that the OLTP TPC benchmark tests perform a very great number of singleton index seeks.
Linear Regression
A natural extension to the idea of linear interpolation is to apply a linear regression (line of best fit) instead:
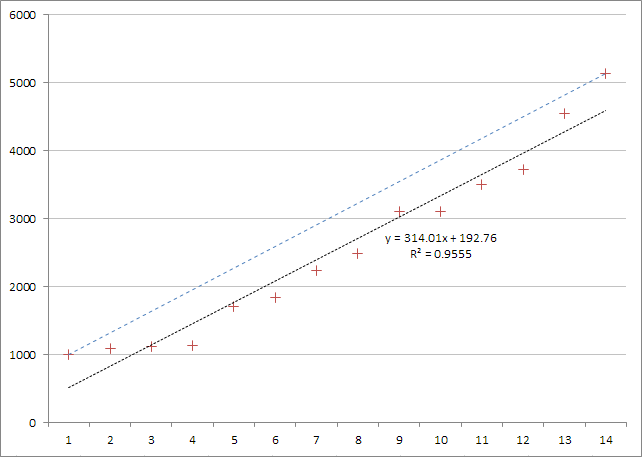
In the diagram, the blue dotted line represents a linear interpolation based on the values of the smallest and highest values in the index only. The black line is obtained by a linear regression of all the data values, and results in a much better fit.
Since every straight line can be represented by a formula of the form y = mx + b, we can completely specify it by recording the values of the m (slope) and b (y-axis intercept) parameters.
The R2 value gives an idea of how good a fit the linear regression line is to the data.
In the present context, the y value represents the indexed value, and the x value is the slot position where that value can be found.
Once we have a linear regression line, we can estimate the slot position for a particular sought index value by solving:
x = (y – b) / m
To use linear regression in a database, we might imagine storing the b and m parameter values somewhere (perhaps in the page header), and deciding whether to apply the technique based on the R2 value.
What Does SQL Server Do?
All this is fine in theory, but does SQL Server really ever use anything except binary search?
To check, I ran tests with a debugger attached to the SQL Server process, and stepped through the calls made while the seek test queries were running.
The call stack below was obtained when running 64-bit SQL Server:

The following call stack comes from 32-bit SQL Server:
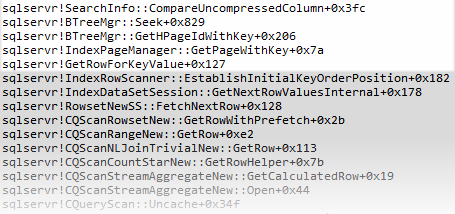
Interestingly, SQL Server follows the same code paths (at least at the call stack level, which is the best we can do without source code) regardless of whether the index is defined as unique or not, and for all the numeric data types I tested (int, bigint, real, float, and decimal with a zero scale).
The performance problem on x64 servers appears to be most pronounced when the key values have a small fixed gap between them.
As we have seen, performance is very much worse on x64 servers compared with x86 versions when the table contains just even or odd numbers (i.e. with a gap of 1 between index entries).
If we change the test to multiply the original entries by a factor of ten (to produce a sequence of 10, 20, 30, 40…) the performance penalty all but disappears, and the x64 unique index test is around 30% faster than the non-unique test.
Conclusions and Further Reading
From the evidence available, my guess is that 64-bit SQL Server does use linear interpolation and/or linear regression instead of binary search under suitable conditions, but that the implementation has edge-case poor performance where the index keys are separated by a small fixed offset.
It seems that we can achieve best performance by using a unique index where possible, and ensuring that keys are, as far as practicable, sequential and contiguous.
See also:
-
B-tree Indexes, Interpolation Search, and Skew by Goetz Graefe
© Paul White
email: SQLkiwi@gmail.com
twitter: @SQL_Kiwi
No comments:
Post a Comment
All comments are reviewed before publication.