I came across a SQL Server optimizer bug recently that made me wonder how on earth I never noticed it before.
As the title of this post suggests, the bug occurs in common JOIN and GROUP BY queries. While it does not cause incorrect results to be returned, it will often cause a poor query plan to be selected by the optimizer.
If you are just interested in the bug itself, you will find a description in the section headed “the bug revealed”. It relates to cardinality estimation for serial partial aggregates.
As the regular reader will be expecting though, I am going to work up to it with a bit of background. The lasting value of this post (once the bug is fixed) is in the background details anyway.
Example Query
Here is a JOIN and GROUP BY query written against the AdventureWorks sample database:
SELECT
COUNT_BIG(*)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
GROUP BY
P.Class
OPTION (MAXDOP 1, RECOMPILE);
One perfectly reasonable query plan possibility looks like this (estimated row counts shown):

After the Merge Join, rows go on to be grouped and counted. This plan has an estimated cost of 1.1 units on my system.
The optimizer has chosen a Merge Join because indexes exist on the join column to provide sorted inputs, and the foreign key relationship between these two tables means that the join will be the efficient one-to-many type.
A Hash Match Aggregate is estimated to be cheaper than the alternative Sort and Stream Aggregate combination in this plan. For reasons that will become apparent shortly, note that the aggregate computes the following expression (a simple count of all the rows):
[Expr1004] = Scalar Operator(COUNT(*))
Partial Aggregates
If you compile the query shown above, you will likely not get the execution plan shown, because the optimizer finds a cheaper plan.
It does this by exploring the option of moving most of the aggregation work under the join. The idea is that reducing row counts as early as possible in a plan generally pays off.
The plan actually selected by the optimizer is this one (estimated row counts again):

The new Stream Aggregate below the join computes the count of rows from the TransactionHistory table, grouped by ProductId.
There are 441 unique ProductId values in the TransactionHistory table, so 441 ProductIds (and associated row counts) go on to be joined with the 504 rows from the Product table. Note that the estimate of 441 groups exactly matches reality.
With a smaller number of estimated rows coming out of the join, the optimizer chooses a Sort and Stream Aggregate combination instead of the Hash Match Aggregate seen previously.
To get the correct query result, the second aggregate uses SUM to add the per-product row counts together.
The estimated cost of this plan is 0.35 units according to SQL Server’s costing model, which explains why the optimizer prefers this plan over the previous one (cost 1.1 units).
Clicking on the new aggregate below the join and looking at its properties, we see that it groups by ProductId and computes a partial aggregate expression:
[partialagg1005] = Scalar Operator(Count(*))
In this case, the expression label is the only way to identify this as a partial aggregate.
The expression computed by the second Stream Aggregate (the one after the Sort) is:
[Expr1004] = Scalar Operator(SUM([partialagg1005]))
This aggregate is a global aggregate: It computes the correct overall result based on partial results calculated earlier in the plan.
In summary: The single COUNT in the original query has been replaced with a partial aggregate COUNT grouped by product, followed by a global aggregate SUM of those counts.
Local and Global Aggregation
This idea of computing part of an aggregate early and combining the partial results later on originated in parallel execution plans.
To illustrate the point, take a look at the following query and execution plan:
SELECT
COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
OPTION (RECOMPILE);
Due to the small size of the sample database, you will need to set the instance’s cost threshold for parallelismconfiguration value to zero in order to get a parallel plan for this query:
EXECUTE sys.sp_configure
@configname = 'show advanced options',
@configvalue = 1;
RECONFIGURE;
EXECUTE sys.sp_configure
@configname = 'cost threshold for parallelism',
@configvalue = 0;
RECONFIGURE;
The execution plan is:

The parallel Stream Aggregate computes the following partial aggregate expression per thread:
[partialagg1003] = Scalar Operator(Count(*))
The serial Stream Aggregate combines the partial aggregates using this expression:
[Expr1002] = Scalar Operator(SUM([partialagg1003]))
In parallel plans, the partial aggregate is often referred to as a local aggregate, since it computes an aggregate that is local to the thread it is running on. In a similar vein, the global aggregate may also be referred to as an exact aggregate.
With four threads, there will be four local aggregations, which are combined to form the final result by the global aggregate, running on a single thread in this example.
One other fact that will be important later on: Notice that the plan above estimates that four rows will be produced by the parallel Stream Aggregate operator — one for each thread.
This plan was generated on a computer with eight processors available to SQL Server. The optimizer always estimates that half the processors will be available for parallel execution. This is a heuristic, and not one that makes an enormous amount of sense to me intuitively, but there you go; it is how it is.
Partial or Local?
To illustrate how inconsistent SQL Server is with the terms ‘partial’ and ‘local’:
SELECT
COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
GROUP BY
TH.Quantity
OPTION (RECOMPILE);

The idea is the same, but the labels are different. Notice that the hash aggregate now has an explicit Partial Aggregate label in the execution plan.
You will only see this helpful change in parallel plans that use a Hash Partial (= Local) Aggregate. There is a sort of reason for this, explained in the next section on memory grants.
The parallel hash aggregate is computing COUNT(*) again, but now it is grouping by Quantity.
The execution plan needs to do a bit more work to get a correct result. Rows from the Index Scan are distributed unpredictably between threads, so each thread can see rows from any or all Quantity groups. The aggregate is still ‘partial’ but this time it is because each thread only sees part of the full row set.
To get the right answer (according to the semantics of the original SQL query) SQL Server goes on to repartition the rows among new threads using Hash Partitioning on the Quantity column.
This step ensures that rows with the same Quantity value always end up on the same thread. To be clear, it says nothing about how many Quantity groups go to each thread.
The repartitioning step just guarantees that rows associated with a particular Quantity value will all end up on the same thread. For efficiency, we certainly hope that the partitioning results in a good distribution of groups among threads, but that is a completely separate issue.
Each Stream Aggregate (one per thread) can now safely compute a SUM of the partial aggregate results it receives on its thread, though it still has to group by Quantity since one thread may receive more than one Quantity group.
The final Stream Aggregate is still a global aggregate, since it uses local (= partial) aggregate results, even though it executes in parallel.
Memory Grants
Another interesting thing about the Hash Match Partial Aggregate is that it never acquires more than a small amount of memory necessary to create a minimally-size hash table.
If the hash aggregate runs out of memory while processing, it simply stops aggregating, and passes individual rows instead. (Note that a partial Stream Aggregate never needs a memory grant, so the same issue does not arise with that operator).
The global aggregate will still produce the correct result, but the query won’t be as efficient (for example, more rows have to move across the Repartition Streams exchange).
The Hash Match Partial Aggregate is an opportunistic performance optimization — it is not required for correctness.
Optimizer Rules
The query optimizer rule that explores splitting ‘ordinary’ aggregates into local and global parts is called GenLGAgg for “Generate Local and Global Aggregate”.
In parallel plans, whether this transformation comes out cheaper depends on whether the plan saves enough cost (for example by reducing the number of rows that flow across the repartitioning exchange) to pay for the overhead of the extra aggregate operation.
In serial plans, there are no exchanges (by definition) so this transformation needs to find another way to pay for itself.
In the earlier example, this was achieved by pushing the partial aggregate below a join such that it reduced the cost of that join (and later operations) enough to at least pay for itself.
There is a second optimizer rule to explore the option of pushing a local aggregate below a join. Its name is LocalAggBelowJoin. Both rules refer to the term Local, as in ‘local to a thread’.
The Bug Revealed
Here’s our original query and the execution plan the optimizer selected again:
SELECT
COUNT_BIG(*)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
GROUP BY
P.Class
OPTION (MAXDOP 1, RECOMPILE);
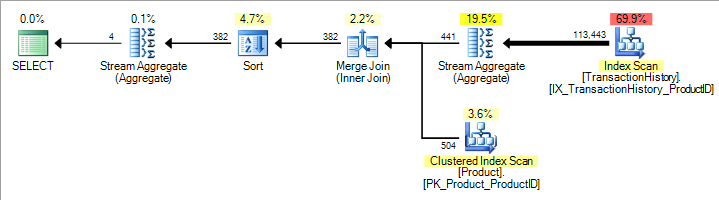
Now here’s the plan produced for exactly the same query, with a MAXDOP 2 hint instead of MAXDOP 1:
SELECT
COUNT_BIG(*)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
GROUP BY
P.Class
OPTION (MAXDOP 2, RECOMPILE);

The estimate of the number of rows emitted by the partial aggregate has doubled, from 441 rows (exactly right, remember) to 882.
If we specify MAXDOP 3, the row estimate trebles to 1323.
At MAXDOP 4, the estimate is 1764.
After MAXDOP 4, no increase occurs on my test machine because it has eight processors, and the optimizer estimates a maximum runtime DOP of half the number of processors available for parallel queries, as noted earlier.
If you have 64 processors, you could get the cost to multiply by 32. To be absolutely clear about this, all these MAXDOP options still result in serial execution plans.
Yes, but I don’t use MAXDOP hints
Neither do I, much — at least not other than specifying one or zero. Anyway, let’s see what happens on the same machine without any hints at all:
SELECT
COUNT_BIG(*)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
GROUP BY
P.Class;

Yikes! The correct estimate of 441 rows has been multiplied by 4 — the maximum possible on this 8-core machine, exactly as if we had specified (MAXDOP 4) to (MAXDOP 8) or even (MAXDOP 0).
Setting the instance-wide max degree of parallelism configuration value to 1 (or using Resource Governor to do the same thing) will result in a correct estimate of 441 rows again (unless a MAXDOPquery hint is specified).
You will also get correct estimates from the partial aggregate if SQL Server is running on a machine with only one processing unit, or if the affinity mask is set such that SQL Server can only see one processor. See the pattern?
Cause & Effects
In short, this cardinality estimation problem comes down to the partial aggregate (and only the partial aggregate) costing itself as if it were running in a parallel plan.
In a parallel plan, each instance of the partial aggregate would produce the estimated number of rows per thread. For a plan estimated to execute at DOP 4, we would get a (correct) multiplier effect on the estimate. For a serial plan, this is just plain wrong.
In the plan above, we were lucky that cardinality estimation for the merge join recognises that it cannot produce more rows than the 504 contained in the Product table because of the foreign key relationship. Nevertheless, the estimates for every operator after the problematic aggregate are still incorrect.
In other plans, this effect can completely change the plan choice above a partial aggregate.
As an example, here is the SQL Server 2012 query from my last post, Is Distinct Aggregation Still Considered Harmful? with the MAXDOP 1 hint:
SELECT
P.ProductModelID,
COUNT_BIG(*),
COUNT_BIG(DISTINCT TH.TransactionDate)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
GROUP BY P.ProductModelID
OPTION (RECOMPILE, MAXDOP 1);

This gives us the efficient new query transformation present in SQL Server 2012 and later — the middle hash aggregate is a partial one.
The exact same query, at MAXDOP 3 or above (or without a MAXDOP hint at all on a machine with 6 cores or more) gives this execution plan:
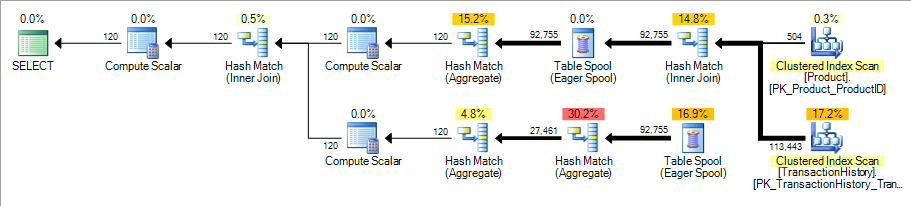
The cardinality estimation bug means we get the horribly inefficient old Eager Table Spool plan!
The optimizer still considers both alternatives. The estimated plan costs explain the choice it makes:
-
The good plan has an estimated cost of 2.8 at
MAXDOP 1(that is, without the partial aggregate costing error). -
At
MAXDOP 2, the good plan’s cost increases to 3.45 units.
The estimated cost of the Eager Table Spool plan is 3.5 units, regardless of the MAXDOP setting (exactly as it should be for a serial plan), so you can see that the spool plan becomes the apparently cheaper option at MAXDOP 3.
(I’m sure it doesn’t need saying again, but the MAXDOP hinted queries here all still produce non-parallel plans.)
The estimated I/O and CPU costs of the partial aggregate operator are also costed as if it were running in parallel at the estimated available DOP, further adding to the costing errors of the plan alternative.
Moreover, the cardinality estimation error will tend to propagate up the plan tree, increasing the costs of upstream operators, and causing larger memory grants to be requested than should be estimated to be necessary.
Overall, the effect is that you are very likely to receive the wrong plan for your query when this bug manifests. The consequences, for non-trivial AdventureWorks queries at any rate, could be severe.
Look out for these estimation errors in any serial plan that features a partial aggregate.
Queries that include a JOIN and a GROUP BY are likely candidates for the GenLGAgg and LocalAggBelowJoin rules to introduce a partial aggregate.
Remember that in serial plans there is no way to know that an aggregate is partial without checking the details of the expressions it computes.
Remember to reset your cost threshold for parallelism is you set it to zero earlier.
Bug status
An archive of the original Connect item for this bug can be found here.
This issue reproduced on all versions of SQL Server from 2005 to 2012 Release Candidate 0 with TF4199 enabled for optimizer fixes (the behaviour on 2005 is even more erratic than described above).
- Update 8 Dec 2011
- Thanks everyone for the votes, Microsoft have responded by confirming the bug. They plan to fix it sometime next year.
- Update 29 Nov 2018
- I am not sure exactly which build of SQL Server 2012 first contained the fix, but the bug continues to exist in SQL Server 2008 R2 SP3 and earlier versions.
© Paul White
email: SQLkiwi@gmail.com
twitter: @SQL_Kiwi
No comments:
Post a Comment
All comments are reviewed before publication.