Let’s say you have a big table with a clustered primary key, and an application that inserts batches of rows into it. The nature of the business is that the batch will inevitably sometimes contain rows that already exist in the table.
The default SQL Server INSERT behaviour for such a batch is to throw error 2627 (primary key violation), terminate the statement, roll back all the inserts (not just the rows that conflicted) and keep any active transaction open:
CREATE TABLE #Big
(
pk integer NOT NULL PRIMARY KEY
);
GO
-- Start with values 1 & 5 in the table
INSERT #Big (pk)
VALUES (1), (5);
-- Our batch transaction
BEGIN TRANSACTION;
-- Insert a batch containing some pre-existing rows
INSERT #Big (pk)
VALUES (1), (2), (3), (4), (5);
-- Show the contents of the table
-- after the insert statement
SELECT pk FROM #Big;
-- Show the transaction count
SELECT tran_count = @@TRANCOUNT;
-- Rollback
ROLLBACK TRANSACTION;
-- Final table contents
SELECT pk FROM #Big;
GO
-- Tidy up
DROP TABLE #Big;
The output is:

Ignoring Duplicates
Let us further imagine that the desired behaviour is that new rows in a batch should be inserted, and any duplicates silently rejected. Most importantly, no error messages should be returned to the client. Ideally, this would be achieved without immediate application changes, and without impacting concurrent users of the table.
This seems like an ideal use for the IGNORE_DUP_KEY option:
CREATE TABLE dbo.Big
(
pk integer NOT NULL,
CONSTRAINT PK_Big
PRIMARY KEY (pk)
WITH (IGNORE_DUP_KEY = ON)
);
GO
-- Unique values
INSERT dbo.Big (pk)
VALUES (1), (3), (5);
GO
-- value 3 already exists
INSERT dbo.Big (pk)
VALUES (2), (3), (4);
GO
DROP TABLE dbo.Big;
That script executes successfully with just a warning (not an error!) about the duplicate key:

The problem
We would like to add the IGNORE_DUP_KEY option to the existing primary key constraint, but the ALTER TABLE command does not have an ALTER CONSTRAINT clause.
We do not want to drop the existing primary key and recreate it with the new option, because the table is large and we want to avoid disrupting concurrent users. Dropping and recreating would result in rebuilding the entire table first as a heap and then as a clustered table again.
Although there is no ALTER CONSTRAINT syntax, we do know that certain constraint modifications can be performed using ALTER INDEX REBUILD on the index used to enforce the constraint. We can, for example, change the type of compression used, the index fill factor, and whether row locking is enabled:
CREATE TABLE dbo.Big
(
pk integer NOT NULL
CONSTRAINT PK_Big PRIMARY KEY
);
GO
INSERT dbo.Big
(pk)
VALUES
(1), (2), (3), (4), (5);
GO
ALTER INDEX PK_Big ON dbo.Big
REBUILD
WITH
(
DATA_COMPRESSION = PAGE,
ONLINE = ON
);
GO
ALTER INDEX PK_Big ON dbo.Big
REBUILD
WITH
(
FILLFACTOR = 90,
ALLOW_ROW_LOCKS = OFF,
ONLINE = ON
);
GO
DROP TABLE dbo.Big;
Unfortunately, we cannot use the same trick to add the IGNORE_DUP_KEY option to the underlying index for the primary key:
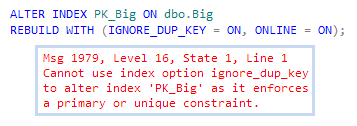
The same error message results even if the ONLINE = ON option is not specified. There will be a range of views about how accurate the error message text is here, but we cannot avoid the fact that the operation we want to perform is not supported by SQL Server.
A creative workaround
One idea is to add a new UNIQUE constraint (or index) on the same columns as the primary key, but with the IGNORE_DUP_KEY option added. This operation can be performed ONLINE:
-- Existing table
CREATE TABLE dbo.Big
(
pk integer NOT NULL
CONSTRAINT PK_Big PRIMARY KEY
);
GO
-- Existing data
INSERT dbo.Big (pk)
VALUES (1), (2), (3);
GO
-- New constraint (or index) with IGNORE_DUP_KEY, added ONLINE
ALTER TABLE dbo.Big
ADD CONSTRAINT UQ_idk
UNIQUE NONCLUSTERED (pk)
WITH
(
IGNORE_DUP_KEY = ON,
ONLINE = ON
);
--CREATE UNIQUE NONCLUSTERED INDEX UQ_idk
--ON dbo.Big (pk)
--WITH (IGNORE_DUP_KEY = ON, ONLINE = ON);
GO
-- Key 3 is a duplicate, just a warning now
INSERT dbo.Big (pk)
VALUES (3), (4), (5);
GO
SELECT pk FROM dbo.Big;
GO
DROP TABLE dbo.Big;
The new arrangement results in the correct final state of the database, without throwing an error. The effect is the same as if we had been able to modify the existing primary key constraint to add IGNORE_DUP_KEY:

Execution plan analysis
There are some drawbacks to this idea, which we will explore in some detail. The drawbacks are significant, so adding the extra index with IGNORE_DUP_KEY is only really suitable as a temporary solution, as we will see.
The first INSERT in the previous script (without the extra constraint or index with IGNORE_DUP_KEY) has a pretty trivial plan; it just shows the constants from the VALUES clause being inserted to the clustered index:

The second INSERT (with the IGNORE_DUP_KEY index) has a more complex plan:

An extra index to maintain
One fairly obvious consequence of adding the new index is that the Clustered Index Insert operator now has to maintain the new nonclustered index too.
I used Sentry One Plan Explorer for the screenshots above because it shows the per-row nonclustered index insert more explicitly than SSMS, where you have to dig into the Object node in the Properties window with the relevant operator selected:
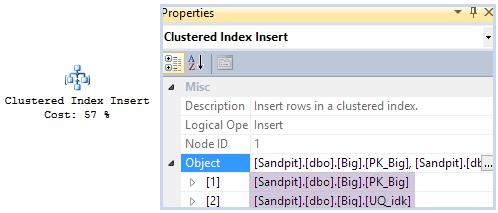
Another way to see the nonclustered index maintenance explicitly is to run the query again with undocumented trace flag 8790 enabled to produce a wide (per-index) update plan:

Besides maintaining the extra index, the IGNORE_DUP_KEY plans seem to be doing a lot of extra work. There are lots of new operators compared with the simple insert.
As you would expect, all the new operators are associated with ignoring duplicate keys, and there are two distinct cases to consider:
1. Rows that already exist
We need to check for INSERT rows that already exist in the base table. This checking is implemented in the execution plan by the Left Semi Join, Index Seek, and Assert operators:

The Index Seek looks for the key value of the current row we are looking to insert. The Semi Join cannot be an Inner Join because that would reject rows where a match was not found (and we need to insert a row in that case).
Nevertheless, the query processor needs to know if an existing row was found with the same key value. The Semi Join sets a value to indicate this, which is stored in the Probe Column:

The Assert operator (known internally as a Stream Check) tests a condition and raises an error if the test fails. Assert operators are often seen in plans that affect columns with CHECK constraints, for example.
In this case, however, the Assert does not raise an error, it emits the ‘Duplicate key was ignored.’ message instead, and only passes a row on to its parent (the Sort operator) if it is not a duplicate.
The test performed by the Assert uses the Probe value stored in the expression labelled [Expr1013] above:
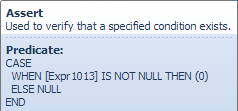
The Assert passes rows where the predicate evaluates to anything other than NULL. If a match was found by the Index Seek (meaning the Probe Column, Expr1013 is not NULL) the Assert does not pass on the row and raises a warning instead.
The following TF 8607 output fragment for the INSERT statement shows the WarnIgnoreDuplicate Assert option (there is nothing equivalent in show plan output unfortunately):

2. Duplicates within the Insert Set
The first check only looks for rows from the insert set that already exist in the base table. The query processor also needs to check for duplicates within the set of values we are inserting.
The Segment and Top operators in the plan combine to meet this requirement:

The Segment adds a bit flag to an ordered stream to indicate the start of a new group of insert key values. The Top operator returns only one row from each group. The overall effect is to remove rows with duplicate index key values.
The Top and Segment execution operators together implement a single physical query processor operator called a “Group-By Top”.
I mention this detail because we need to be familiar with the internal name to understand the TF 8607 output, which indicates that this operator also emits a `Duplicate key was ignored.’ warning when it encounters a group with more than one key value:

Locking
Another downside is that adding the new index means that locks will now be taken on the nonclustered index when checking for existing rows:

It might surprise you to learn that the index seek acquires Range S-U locks on the nonclustered index (extract from the documentation link below):

Key-range locks like this are only taken under the SERIALIZABLE isolation level, but our INSERT statement uses them whatever isolation level the user runs the query under (for example, range locks are still taken if the session is running under the default READ COMMITTED isolation level).
SQL Server raises the effective isolation level to SERIALIZABLE for the Index Seek (and just for that operator) because it needs to be sure that if it does not find a match in the index, that situation remains the same until it inserts the new row.
The Index Seek is looking for a key value that does not exist, so a range lock is necessary to prevent a concurrent transaction inserting a row with that key value in the meantime.
There is no existing key in the index to lock (because the row does not exist) so a range lock is the only option. If SQL Server did not do this, our INSERT query might fail with a duplicate key error despite the IGNORE_DUP_KEY setting (we check for a row, don’t find it, someone else inserts it, then we try to insert a duplicate).
The optimizer adds a SERIALIZABLE hint for the Index Seek operator (internally, a physical Range operator) as we can see using another extract from the TF 8607 output:

The execution plan is also forced to use the nonclustered index with the IGNORE_DUP_KEY setting for this seek (FORCEDINDEX) and an update lock (UPDLOCK) hint is also given to help prevent conversion deadlocks. Nevertheless, you may find increased deadlocking if you choose to add an extra IGNORE_DUP_KEY index like this.
Permanent solutions
Adding a nonclustered unique index with the IGNORE_DUP_KEY option and the same key as the clustered primary key allowed us to solve an immediate problem without code changes, while keeping the table online, but it does come at a price.
The execution plan is much more complex than the original INSERT, and there is a chance of deadlocks. The biggest performance impact of adding the extra index is of course the cost of maintaining it, meaning we need to look at a more permanent solution via a code change.
IGNORE_DUP_KEY
The (trivial) test I am going to run inserts 5000 unique rows from my table of numbers into the table we have been using so far. To establish a baseline, we will first look at the execution plan for an INSERT to the table with a nonclustered IGNORE_DUP_KEY index:
CREATE TABLE dbo.Big
(
pk integer NOT NULL
CONSTRAINT PK_Big PRIMARY KEY
);
ALTER TABLE dbo.Big
ADD CONSTRAINT UQ_idk
UNIQUE NONCLUSTERED (pk)
WITH
(
IGNORE_DUP_KEY = ON,
ONLINE = ON
);
INSERT dbo.Big
(pk)
SELECT
N.n
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 5000;
The execution plan is:

This plan is very similar to the earlier one, though a Merge operator is used to perform the Left Semi Join, and a wide update plan has been chosen, making the Nonclustered Index Insert easier to see. The other main feature is an Eager Table Spool, required for Halloween Protection.
The estimated cost of this execution plan is 0.363269 cost units on my instance.
Modified INSERT
The first code alternative to the extra index is to modify the INSERT statement to check that rows do not already exist in the destination. There are a number of SQL syntaxes for this, each with different characteristics and performance in different circumstances.
To keep things simple, and because I only want to make a couple of specific points here, I have chosen my simple example to produce the same execution plans for all the common syntax variants. The first thing to do is to drop our extra constraint:
ALTER TABLE dbo.Big
DROP CONSTRAINT UQ_idk;
Now we can evaluate the modified INSERT statement:
-- I generally prefer this syntax
INSERT dbo.Big
(pk)
SELECT
N.n
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 5000
AND NOT EXISTS
(
SELECT *
FROM dbo.Big AS B
WHERE B.pk = N.n
);
-- Alternative syntax using EXCEPT
INSERT dbo.Big
(pk)
SELECT
N.n
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 5000
EXCEPT
SELECT
B.pk
FROM dbo.Big AS B;
-- Not recommended
INSERT dbo.Big
(pk)
SELECT
N.n
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 5000
AND N.n NOT IN
(
SELECT
B.pk
FROM dbo.Big AS B
);
All three variations produce the same execution plan:

This has an estimated cost of 0.0981188 units – much cheaper than the 0.363269 cost seen previously.
The Halloween Protection spool still features in the plan, but there is a weakness in our queries that you might have already spotted: We are not doing anything to protect against duplicate key violation errors in case someone else inserts a row after we have checked to see if it exists, but before we insert it.
The query optimizer added a SERIALIZABLE hint when it added an existence check, so if avoiding errors is important to us, we need to do the same:
INSERT dbo.Big
(pk)
SELECT
N.n
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 5000
AND NOT EXISTS
(
SELECT *
FROM dbo.Big AS B
WITH (SERIALIZABLE) -- New
WHERE B.pk = N.n
);
We do not need the UPDLOCK hint for two reasons. First, the engine automatically takes update locks for us when reading the source table. Second, we are reading from the same index we are inserting to (not reading from a nonclustered index and inserting to the clustered index) so the previous deadlock scenario is not applicable.
Using MERGE
Another option is to use the WHEN NOT MATCHED feature of the MERGE statement. This time we will add the necessary SERIALIZABLE hint up front:
MERGE dbo.Big
WITH (SERIALIZABLE) AS B
USING
(
SELECT
N.n
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 5000
) AS S
ON S.n = B.pk
WHEN NOT MATCHED THEN
INSERT (pk)
VALUES (s.n);

This plan has an estimated cost of 0.0950127 units – slightly less than the 0.0981188 units for the modified INSERT plans. Some of this improvement is due to the lack of a Halloween Protection spool, for interesting reasons covered in depth in my linked series.
These are not meant to be performance tests by any stretch of the imagination. There are any number of subtle factors that will affect the execution plans and run times for different numbers of rows, different distributions, and so on.
I should stress that I normally find MERGE plans perform less well than separate INSERT/UPDATE/DELETE more often than not. Anyway, in case you are interested, typical performance results on my machine for this specific test are (INSERT first, then MERGE), timings in milliseconds:

IGNORE_DUP_KEY and Clustered Indexes
When IGNORE_DUP_KEY is specified for a unique clustered index (primary key or otherwise), duplicates are handled by the storage engine rather than the query processor.
For example:
CREATE TABLE dbo.T
(
pk integer NOT NULL
CONSTRAINT PK_idk
PRIMARY KEY
WITH
(
IGNORE_DUP_KEY = ON
)
);
INSERT dbo.T
(pk)
VALUES
(1), (1), (2), (3);
The execution plan shows none of the complexity of the nonclustered index case:
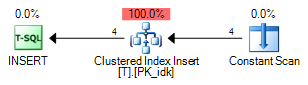
The TF 8607 output contains none of the query processor hints to ignore duplicates and raise warnings:

The IGNORE_DUP_KEY side of things is handled entirely by the storage engine. If it finds a row in the unique index where it was going to insert one, it flags a warning but does not try to insert (which would cause an error).
The estimated cost of this query plan is identical whether the unique clustered index has IGNORE_DUP_KEY or not — there is no extra work for the query processor.
If you are wondering why the same mechanism is not used for a nonclustered unique index with the IGNORE_DUP_KEY option, my understanding is it is because the Clustered Index is always updated before the nonclustered ones (even in a narrow plan). By the time the storage engine detected a duplicate in the nonclustered index, it would have already added the row to the base table. To avoid this, the query processor handles IGNORE_DUP_KEY for nonclustered indexes.
Acknowledgement
This post was inspired by a post by Daniel Adeniji and our subsequent discussion of it. My thanks to him for permission to analyze the issue further here, and for allowing me to reference his work.
The issue described here may not accurately reflect Daniel’s original problem — I used a certain amount of artistic licence. Even if the specific issue is not particularly interesting to you, I hope you enjoyed some aspects of the analysis and maybe picked up some new information along the way.
© Paul White
email: SQLkiwi@gmail.com
twitter: @SQL_Kiwi
No comments:
Post a Comment
All comments are reviewed before publication.